-
 Section menu
Section menu
This document contains only my personal opinions and calls of judgement, and where any comment is made as to the quality of anybody's work, the comment is an opinion, in my judgement.
[file this blog page at: digg del.icio.us Technorati]
The Lustre filesystem is usually used for large parallel cluster storage pools, but it can be used as well as a replacement for NFS for NAS storage for workgroups, and it has some advantages for that:
NFS has few potentially significant advantages over Lustre:
These could be some typical installations of Lustre as a small scale NFS replacement for workgroups:
This single server would be running the MGS, MDS, OSS, with the MDTs and the OSTs ideally on different storage layer devices.
This configuration is the most similar to that of a single NFS server.
Each server as in the previous case, running separate instances, but with the backup MGS and MDS for one instance on the main server for the other instance.
If the two servers share storage (not necessarily a good idea for two separate Lustre instances), or at least share storage paths, the backup OSS for one instance could also run on the main server for the other instance.
One server would have the primary MGS and MDS and one OSS, and the other the backup MGS and MDS and another OSS, and load would be parallelized among the two OSSes.
Two servers, one with the main MGS and MDS and OSS, and the other with the backup one, and with the OSTs replicated online between the two servers.
The replication could be achieved with the mirroring facilities in Lustre 2 (which have not appeared yet), or by the traditional method of using DRBD pairs as the storage layer.
The Lustre server components require kernel patches, which are not necessarily available for the most recent kernels.
Conceivably one can have more than 1-2 OSSes, but then it is no longer quite a workgroup server equivalent to an NFS server.
An important detail is to avoid the lurid temptation of using the same Lustre instance or even storage layer for a massively parallel cluster workload and for the workgroup server, as they need very different storage layers and very different tuning.
Reading the announcement of the release of SUSE Linux SLES SP2 I was astonished by two big aspects of the announcement:
service packincludes major API and ABI updates (kernel, C compiler, etc.). I haven't followed SLES much, but the other major enteprise distributions like RHEL and Debian stable have a policy of not upgrading package versions (with some rare exceptions), but backporting security fixes or some rare enhacements.
Another big change coming with SLES 11 SP2 is that SUSE Linux is mainstreaming the btrfs file system and Linux containers.
"I think that there is no reason to use ext3 anymore," says Pfeifer. "We think btrfs is ready and the best choice."
By the way, you can still use the XFS file system if you want, which has been in the SLES distro since version 8.0, and you can read ext4 file systems and migrate them to btrfs even though ext4 is not itself supported in SLES 11.
But despite all of this variety, Pfeifer says that the snapshotting features of btrfs as well as the scalability are why SUSE Linux is recommending it as the root file system for SLES 11 SP2.
A significant addition is that of a feature they call LXC (also 1, 2) which is containers, or operating system context virtualization, instead of paravirtualization or full hardware virtualization. This is analogous to Linux VServer or OpenVZ and since LXC is mostly a set of container primitives for the kernel probably both will end up based on it.
Having just mentioned viewing angles as important for selecting LCD panels it may be useful to mention that this relates to the type of display, and the best have one of various types of non-TN display but it is often difficult to figure out which type of display is used for a monitor.
Empirically, by observing a significant number of monitor
specifications, it turns out that the viewing angle of 178/178
seems conventional to indicate IPS and PVA/MVA displays,
because I can't believe that they all have exactly 178/178
as viewing angle. Indeed I have noticed that there are four
probably conventional
viewing angles
reported by monitor manufacturers, and they tend to be proxies
for display type and quality:
TNdisplays, where moving the point of view off the centre horizontally usually results in some significant yellowing of colors, and vertically results in massive contrast change.
121215 update: the viewing angle should be measured with a CR ≥ 10, while some manufacturers have taken to publish viewing angles at a CR ≥ 5, where 178/178 is often equivalent to 170/160 at a CR ≥ 10, and even a very serious company like NEC indulge in this:
Viewing Angle [°]: 170 horizontal / 160 vertical (typ. at contrast ratio 10:1); 178 horizontal / 178 vertical (typ. at contrast ratio 5:1)
Don't be mislead by NEC's quoted specs of 178/178 viewing angles. This model has a TN Film panel and they have quoted a misleading spec on their website using a CR>5 figure instead of the usual CR>10.
I would like to complement my excellent Philips 240PW9 IPS monitor with a newer Philips monitors, but both their current 16:10 aspect ratio models (240B1, 245P2ES) are specified with 178/178 at CR ≥ 5, and indeed they seem to have TN displays.
They do have several monitors with VA displays, which have 178/178 at CR ≥ 10, but they are all in 16:9 aspect ratio.
I was asked recently by a smart person how I buy computing
equipment, and this was in an enterprise
context. Interesting question, because my approach to that is
somewhat unusual, because I care about resilience more than
most as the computing infrastructures on which I work tend to
be fairly critical. Some of my principles are:
One of my general principles is that there are no generic commodities; each product as a rule has fairly important but apparently small differences, and these usually matter.
For example
viewing angle for LCD displays,
ability to change error recovery timeouts
for disk storage,
endurance for flash
SSDs, or
power consumption for CPUs, or vibration for cases, or
quality of power supply.
Reading reviews about the products is usually quite important, because the formal specifications often omit vital details, or the importance of the details is hard to determine. I also whenever possible buy samples of the most plausible products to review them myself (for example LCD monitors).
My aim is to ensure that different items have different failure modes, therefore unlikely to happen simultaneously. Because redundancy is worthwhile only as long as failures are uncorrelated.
Most hardware is buggy, most firmware is buggy, most interfaces between components of a system rely on product specific interpretations, most manufacturing processes have quirks. This is an ancient lesson, going back to the day where all Internet routers failed because of a single bug, and probably older than that.
My attitude is that some limited degree of diversity is better than no diversity, and better than a large degree of diversity (which creates complications with documentation and spare parts).
For example I would avoid having disk drives all of the same brand and type in a RAID set; I would rather have them from 2-3 different manufacturers, just like having two core routers from different manufacturers, or rather different main and backup servers, and ideally in different computer rooms with different cooling and electrical systems.
Given a choice I usually prefer to buy several cheaper even if lower end products than fewer higher end ones, because I prefer redundancy among systems than within systems.
In large part because my generic service delivery strategy is to build infrastructures that look like a small Internet with a small Google style cloud.
This is in effect diversity by numbers, because usually for my users having something working all of the time is better than having everything or nothing working. Thus for example I would rather have a lower end server every 20 users than a high end one for 200 users. Or having 2 low end mirrored servers every 40 users.
Usually there are on the price/quality curve five interesting inflection points:
Most of the time I go for the two intermediate between best price/quality and lowest price or best quality.
Usually I try to buy products plus their spares and some years of extra manufacturer warranty with the original product purchase. A large part of this is to avoid doing multiple invitations to tender and purchase orders, which can take a lot of time, and it also often results in better pricing from the supplier, as their salesperson is more motivated.
But also because I tend to buy non-immediate warranty service, because I prefer having onsite spares and doing urgent repairs by swapping parts without calling a manufacturer technician.
Also, and very importantly, many product items will outlast their warranty, and at that point it will be difficult to find cheap spares, so stocking them is usually a good idea.
There are principles of purchasing that are of more tactical importance, for example:
From a previous experience I learned also that when selecting the winning tenders is it best to use a rule to select the second lowest price (and to let this be known in advance) because as a rule the lowest price is unrealistic. Also it is often important to structure invitations to tender in a few lots to be able to select multiple suppliers, again for diversity, but of supplier, not of product, because even if they sell the same product, different suppliers can handle the supply very differently.
It may seem obvious, but it is useful to note that RAID1 has some very useful properties for both performance and resilience, especially when coupled with current interface technologies.
For resilience a RAID1 on a SATA or SAS interface have the very useful property that one or both mirror drives can be easily taken out of a failed server and put in a replacement one, even hotplugging them, and that adding a third mirror and then taking it out does a fast image backup but subject to load control.
For performance, good RAID1 implementations like in Linux MD use all mirrors in parallel when reading. This means that a whole-tree scan like for an RSYNC backup does not interfere that much with arm movement because of ordinary load.
As previously reported I have been astonished by how different antialiased glyps look on light and dark backgrounds so I have been investigating again font rendering under GNU Linux, as fonts and good quality rendering are a topic that I am interested in as it impacts the many hours I work on computers, like monitor quality (1, 2 3 4, etc.).
The most important finding is the advice that I have received
that the non-monochrome character stencils rendered by
the universally used
Freetype2
library
should be gamma
adjusted when composited by the application onto the
display.
Unfortunately none of the major GNU/Linux
GUI
libraries gamma-adjust character glyphs. So I have tried
adjusting overall display gamma instead, via monitor hardware
gamma settings and X window system
software gamma settings, and Adjusting gamma correction either
way has a very noticeable effect on the relative weights of
monochrome and antialiased glyphs, as it affects the apparent
darkeness of the grayscale pixels of the latter.
It turns out that for a gamma of 1.6-1.7 there is a match between the apparent weight of the monochrome and antialiased versions in the combined screenshots I was looking at. This is not entirely satisfactory, because gamma adjustment to 1.6-1.7 is a bit low and colors look a bit washed out. However I have looked at the general issue gamma correction for excellent monitor and using the KDE SC4 gamma testing patterns it turns out that to be able to distinguish easily the darkest shades of gray I should set the monitor gamma correction to 1.8, not 2.2; this makes GUI colors look less saturated than I prefer, but makes photos look better, which may be not so surprising: 1.8 is the default gamma correction for Apple computer and monitor products, which are very popular in the graphics design sector, and I suspect that many cameras may be calibrated by default for output that looks best at 1.8 on an Apple product.
However by my eyes the stencil computed by Freetype2 seems good for an even weaker gamma, which desaturates colors too much, so I have decided to remain on gamma 1.8 for the time being.
To check this out I have been using the ftview toold that is part of Freetype2 and or using xterm with the -fa option to give it a full Fontconfig font pattern, for example:
$ XTHINT='hinting=1:autohint=1:hintstyle=hintfull' $ XTREND='antialias=1:rgba=rgb:lcdfilter=lcdlight' $ xterm -fa "dejavu sans mono:size=10:weight=medium:slant=roman:$XTHINT:$XTREND"
Or with gnome-terminal or gedit and then using gnome-appearance-properties to change the parameters.
The results are often very surprising, as there seems to be not much consistency to the, for example with some fonts subpixel antialiasing results in bolder characters, and with others it does not, and similarly for autohinting, which sometimes results in very faint characters, and often changes the font metrics very visibly, typically by widening the glyphs.
After my
note about the COW
version of ext3 and ext4 I realize that I have been
confusing a bit log structured
and COW
filesystem implementations.
Most log structured filesystems are also COW, but the two are independent properties, and for example Next3 is COW but is not log structured, and conceivably a log-structured filesystem can overwrite data if rewritten instead of appending it to the log.
However it is extremely natural for a log structure filesystem to append instead of overwrite, and I don't know of any that overwrite.
Also usually a COW filesystem will act very much like a
log-structured one even if it is not log structured, because
the every time an extent is updated, some new space needs to
be allocated, and most space allocators tend to operate by
increasing block address. Even if filesystems that are not log
structured try to allocate space for blocks next or near to
the blocks they are related to, if some blocks are updated
several times, their COW versions will by necessity be
allocated ever further. Therefore in some way COW filesystem
that are not log structured tend to operate as a collection of
smaller log structured filesystems, usually related to the
allocation groups
in which they are usually
subdivided.
The video of the talk by Kirk McKusic about updates to the FFS used in many BSD has many points of interest for filesystem designers and users, because it describes a rather different approach to recovery from most other filesystem designs.
Before noting some of the points that interested me, description of the four approaches that most filesystems use for recovery:
fsck) after a failure to find and correct, more or less brutally. This is the approach for filesystems like FAT32, sysv, ext2.
journal(also known as an
intent log) before actually performing it, so recovery from failure can be done by reading pending changes from the log and effecting them. This requires doubling the IO load for metadata. This is the approach used by JFS, ext3 XFS, and many others.
soft updatesand involves keeping two different metadata states, one on persistent storage which is somewhat older than one cached in volatile memory, and synchronizing them piecemeal on cache pressure or timer expiry
The talk is about an extension to the soft updates system, as it is not complete: because of the cost some operations are not fully synchronized to disk.
Some of my notes:
inodesand blocks to the respective free lists.
UNIXAPI as being too complex.
fsck source of 6,100 lines.I was impressed with the effort but not with the overall picture, because the BSD FFS is already a bit too complicated, soft updates require a lot of subtle handling, and the additional journaling requires even more subtlety. The achieved behavior is good, but I worry out the maintainability of the code implementing it. I prefer simpler designs requiring less subtlety most importantly for critical system code which is also probably going to be long lived.
In my previous notes on
parameters to classify RAID levels
I mentioned synchronicity
, which is that
the devices in the
RAID
set are synchronized, so that they are at the same position at
the same time all the times.
This parameter which is the default for RAID2 (bit parallel) and RAID3 (byte parallel) is actually fairly important because it has an interesting consequence: that it implies that stripe reads and writes always take the same time, at the cost of reducing the IOPS to those of a single drive, as the components of a full physical stripe is avalable at the same time.
In particular for RAID setups with parity it means that the logical sector size for both writing and reading is the logical stripe size, and that there is no overhead for rebuilding parity as a full physical stripe is also available on every operation. It is therefore quite analogous to RAM interleaved setups with ECC.
This is particularly suitable for RAID levels where the
physical sector size is smaller than the logical sector size,
that is where the physical sector size is a bit or byte as in
RAID2 or RAID3, as one wants the full logical stripe in any
case, but it can be useful also with small strip sizes made of
small physical sectors. For example the case where the logical
stripe size is 4KiB and the physical sector is 512B, which
seems to be the case
for DDN storage product
tiers
.
The big issue with synchronicity of a RAID set is that on
devices with positioning arms
it
synchronizes the movement of the arms, which reduces the
achievable peak IOPS compared to independently moving
arms. Therefore the above applies less to devices with uniform
and very low access times like flash
based
SSDs which don't
have positioning arms.
In general synchronized RAID sets are good for cases where fairly high read and write rates are desired with low variability for single stream sequential transfers, on devices with positioning arms and this was it is recommended by EMC2, as in effect the RAID set has the same performance profile as a single drive of higher sequential bandwidth.
My favourite filesystem is clearly so far
JFS
because of its excellent, simple, design that delivers high
performance in a wide spectrum of situations, and quite a few
important features. Its design is based on pretty good
allocation policies, delivering usually highly contiguous
files, and the use of
B-trees
in all metadata structures as the default indexing mechanism,
which is an excellent choice. Since the same B-tree code is
used, JFS is also remarkably small. Indeed as I noted I have
switched with regret from JFS
to XFS
also because I trust more a simpler, more stable code
base.
As a simple and somewhat biased measure of the complexity of the design of a filesystem I have take the compiled code for some filesystem from the 3.2.6 Linux version (the compiled Debian package linux-image-3.2.0-1-amd64_3.2.6-1_amd64.deb) and mesured code and other size withing them:
$ size `find fs -name '*.ko' | egrep 'bss|/(nils|ocfs2|gfs2|xfs|jfs|ext|jbd|btr|reiser|sysv)' | sort` text data bss dec hex filename 443528 7756 208 451492 6e3a4 fs/btrfs/btrfs.ko 56939 712 16 57667 e143 fs/ext2/ext2.ko 145583 11232 56 156871 264c7 fs/ext3/ext3.ko 303003 23208 2360 328571 5037b fs/ext4/ext4.ko 181901 5608 262216 449725 6dcbd fs/gfs2/gfs2.ko 44192 3280 40 47512 b998 fs/jbd/jbd.ko 52418 3312 120 55850 da2a fs/jbd2/jbd2.ko 132904 2084 1048 136036 21364 fs/jfs/jfs.ko 70677 4104 119464 194245 2f6c5 fs/ocfs2/cluster/ocfs2_nodemanager.ko 174909 696 60 175665 2ae31 fs/ocfs2/dlm/ocfs2_dlm.ko 17706 1376 16 19098 4a9a fs/ocfs2/dlmfs/ocfs2_dlmfs.ko 665041 74248 2232 741521 b5091 fs/ocfs2/ocfs2.ko 3869 712 0 4581 11e5 fs/ocfs2/ocfs2_stack_o2cb.ko 5428 872 8 6308 18a4 fs/ocfs2/ocfs2_stack_user.ko 6116 1640 40 7796 1e74 fs/ocfs2/ocfs2_stackglue.ko 173240 1304 4580 179124 2bbb4 fs/reiserfs/reiserfs.ko 24209 728 8 24945 6171 fs/sysv/sysv.ko 472490 59528 392 532410 81fba fs/xfs/xfs.ko
Note: in the above it must be noted that the size of the jbd module should be added to that of ext3 and that of jbd2 to ext4 and ocsfs2.
My comments:
In a recent entry I presented a way to understand RAID types giving also a table where common RAID types are classified using the parameters I proposed. There are other less common RAID types that may be useful to classify using those parameters:
| Set type | Set drives | Physical sector, Logical sector |
Strip chunk, Strip width |
Chunk copies, Strip parities |
Synch. | Sector map | Strip map |
|---|---|---|---|---|---|---|---|
| RAID10 o2, RAID1E |
3 | 512B, 512B | 4KiB, 12KiB | 1, 0 | 0 | rotated copy | ascending |
| RAID10 f2 | 2×(1+1) | 512B, 512B | 4KiB, 8KiB | 1, 0 | 0 | chunk copy | split rotated |
In the above rotated copy
means that each
chunk is duplicated and the copies are rotated around the each
stripe, so that with the example 3×drive array, the
first chunk is replicated on drives 1 and 2, the second on
drives 3 and 1, the third on drives 2 and 3, and so on.
While split rotated
means that disks are
split in two, and copies of a chunk are written to the top
half of one disk and the bottom half of the next (in rotation
order) disk.
While reading flash
SSD
notes and reviews I have found
a report that several had failed for a single user
but that he was so pleased with their performance that he just
kept buying them. There were several appended comments
reporting the same, as well as several reporting no
failures. The nature of the failures is not well explained,
but there are some hints, and there are some obvious
explanations:
endurancethat is a consequence of excessive write rates. This may be due to early flash SSD products having no
overprovisioning, or more commonly and simply much higher write rates, especially unaligned ones.
Change Log:
- Changes made in version 0009 (m4 can be updated to revision 0309 directly from either revision 0001, 0002, or 0009)
- Correct a condition where an incorrect response to a SMART counter will cause the m4 drive to become unresponsive after 5184 hours of Power-on time. The drive will recover after a power cycle, however, this failure will repeat once per hour after reaching this point. The condition will allow the end user to successfully update firmware, and poses no risk to user or system data stored on the drive.
This firmware update is STRONGLY RECOMMENDED for drives in the field. Although the failure mode due to the SMART Power On Hours counter poses no risk to saved user data, the failure mode can become repetitive, and pose a nuisance to the end user. If the end user has not yet observed this failure mode, this update is required to prevent it from happening.
If you are using a SAS Expander please do not download this Firmware. As soon as we have a Firmware Update that will work in these applications we will release it.
Note that none of these issues have to do with hardware failure, which is extremely unlikely for electronics with no moving parts after just one year or so of operation. They are all issues with overwear or with firmware mistakes.
Of these the excessive write rates seem the most common as most commenters note that they can still read from the device but not write.
While I have tuned my IO subsystem to minimize the frequency of physical writes and verified that write transfer rates be low I suspect that many users of SSDs are not aware of the many WWW pages with advice on how to minimize writing to flash SSDs for various operating systems.
Quite surprisingly I have completely missed that there is a version of the ext3 filesystem called Next3 which allows transparent snapshots, using COW like BTRFS. There is also a version of this change for the newer ext4 filesystem.
While ext3 and ext4 are old designs and should have been replaced by JFS long ago, they are very widely adopted, because they are in-place upgrades to each other and to the original ext2 filesystem. Both Next3 and Next4 are also in-place upgrades, and snapshotting and COW itself are very nice features to have, so they should be much more popular.
But there is a desire among some opinions leaders of the Linux culture to favour instead a jump to BTRFS which is natively COW and provides from the beginning snapshots as well as several other features.
I am a bit skeptical about that, because it is a very new design that may have yet more limited applicability than its supporters think, and while it can be upgraded in place from ext3 and ext4, it is a somewhat more involved operation than just running them with the additions of COW and snapshotting.
This probably is particularly useful for cases where upgrading to newer kernels with more recent filesystems is difficult because of non technical reasons, for example when policies or expediency mandate the use of older enterprise distributions like RHEL5 or even RHEL6 or equivalent ones.
Just as there are cases where RAID5 may be a reasonable choice there may be cases where RAID6 (or in general double parity) may be less of a bad choice than I have argued previously.
After in many installation it does not handle terribly, and even if usually that's because it is oversized, there are cases where it is less bad. These are conceivably those in which its weaknesses are less important, that is when:
RMWis low.
Stripesize is small, and this implies a small
chunksize and a low number of drives, to minimize the chances of misaligned writes, or too small writes, triggering RMW, and to minimize its cost if it occurs.
In the above a small stripe presumably is not going to be larger than 64KiB, and ideally not 16KiB or less, and that is because in effect the physical sector size of a RAID6 set is the logical stripe size.
It is also interesting to note that most filesystems currently default to a 4KiB block size, so that the stripe size can be transparently that size, with no performance penalty. Regrettably the physical sector size of many new drives is now 4KiB instead of the older 512B, and the physical sector size is the lower bound on chunk size.
Given the points above the setups that may make sense, if data is mostly read-only and RAID5 is deemed inappropriate, seem to be:
More than 8 drives seems risky to me, and leads to excessively large stripes. I have seen mentioned a 16+2 drive arrays (or even wider) with a chunk size of 64KiB, for a total stripe size of 2MiB, and that seems pretty audacious to me.
The most sensible choices may be:
| Drives | Chunk size | Stripe size |
|---|---|---|
| 4+2 | 1KiB | 4KiB |
| 4+2 | 4KiB | 16KiB |
| 6+2 | 2KiB | 12KiB |
| 6+2 | 4KiB | 24KiB |
| 8+2 | 512B | 4KiB |
| 8+2 | 4KiB | 32KiB |
The main difficulty here is that 4+2 and 6+2 are quit3e equivalent to two 2+1 or 3+1 RAID5s, and in most every case the latter may be preferable, if one can do the split.
One strong element of preferability is that the two RAID5 arrays are then ideally more uncorrelated, and when one fails and rebuilds, the other is entirely unaffected.
Another one is that most RAID5 implementations do an abbreviated RMW involving only the chunk being written and the block being written, and this coupled to the lower number of drives can give a significant performance advantage on writes. Conversely the wider stripe of a single RAID6 can give better read performance for larger parallel reads.
But as to that one could argue that at least a 4+2 set could be turned into a 4+1 plus warm spare drive alternative set, where when one drive fails the warm spare is automatically inserted, and the impact of the rebuild under RAID5 is probably much better than the rebuild under RAID6, even for a single drive failure.
So unless one really needs a parallelism or a volume that must be 4 or 6 drives wide, I would prefer split RAID5 sets, or a 4+1 plus spare.
The one case where RAID6 cannot be easily replaced by RAID5 is the 8+2 case, because if one really needs 8 drives of capacity or their parallelism, and cannot afford 16 drives for a RAID10 set, and there are very few writes, that is a least bad situation. Especially of the case with 512B chunk size, on drives that have 512B physical sectors. It gets a fair bit more audacious with drives with 4KiB physical sectors and thus a 32KiB stripe size, but it is still doable, even if in an even narrower set of cases.
There are now for
RAID
levels
some standard definitions
and I was amused to see that RAID2 and RAID3 were specifically
defined to be bit and byte parallel checksum
setups, and RAID4 and RAID5 to be block level checksum setups
with different layouts, and RAID5 to be RAID6 with two checksums.
These definitions resemble the original ones, but it is quite
clear that there is some structure to them that is not quite
captured by the definitions of levels. For example RAID2 and
RAID3 could have dobule checksums too, and the real difference
between RAID2 and RAID3 versus RAID4 and RAID5 is that in the
former the unit of parallelism is smaller than a logical sector
and in the latter it is a
logical sector, and this gives important differences.
The way I understood RAID levels for a long time is that
there is something which is a strip
, which
is replicated across the set of drives, and the different
levels are just different way to arrange parallelism,
replication and checksums within a strip, and to map a strip
and a set of strips onto physical hardware units, and this
provides a much more general way of looking at RAID. More
specifically all RAID levels can be summarized with these
parameters:
parity:
In the above parameters arguably logical sector and strip chunk are somewhat similar and redundant concept, or that strip chunks are a sector map function, and that are chunk copies and parity are the same thing, because:
These parameters can be used to define the standard raid level mentioned above, and here are some example values for each level:
| Set type | Set drives | Physical sector, Logical sector |
Strip chunk, Strip width |
Chunk copies, Strip parities |
Synch. | Sector map | Strip map |
|---|---|---|---|---|---|---|---|
| JBOD | 1 | 512B, 512B | 512B, 512B | 0, 0 | n.a. | 1-to-1 | ascending |
| RAID0 | 4× | 512B, 512B | 4KiB, 16KiB | 0, 0 | 0 | 1-to-1 | ascending |
| RAID1 | 1+1 | 512B, 512B | 4KiB, 4KiB | 1, n.a. | 0 | 1-to-1 | ascending |
| RAID01 | 2×+2× | 512B, 512B | 4KiB, 8KiB | 1, 0 | 0 | strip copy | ascending |
| RAID10 | 2×(1+1) | 512B, 512B | 4KiB, 8KiB | 1, 0 | 0 | chunk copy | ascending |
| RAID2 | 8×+1 | 512B, 8b | 8b, 8b | 0, 1 | 1 | 1-to-1 | ascending |
| RAID3 | 8×+1 | 512B, 8B | 8B, 8B | 0, 1 | 1 | 1-to-1 | ascending |
| RAID4 | 2×+1 | 512B, 512B | 4KiB, 8KiB | 0, 1 | 0 | 1-to-1 | ascending |
| RAID5 | 2×+1 | 512B, 512B | 4KiB, 8KiB | 0, 1 | 0 | rotated | ascending |
| RAID6 | 4×+2 | 512B, 512B | 4KiB, 16KiB | 0, 2 | 0 | rotated | ascending |
The main message is that RAID is about different choices are different layers of data aggregation, how logical sectors are assembled from physical sectors, how strips are assembled from logical sectors, and how these maps onto physical devices.
Almost any combination is possible (even if very few are good), and there is really no difference between RAID2 and RAID3 except the size of the physical sector, and between RAID5 and RAID6 except the number of parity chunks, and those numbers are arbitrary.
It is also apparent that less common choices are possible, for example having both chunk copies and strip parities (which make sense only if the strip width is greater than the chunk size).
It is possible to imagine finer design choices, for example to have per-chunk parities, but that makes sense only if one assumes that individual logical sectors in a chunk can be damaged.
I have been reading some recent reviews of several flash based SSDs, usually of one model with performance tests comparing it to several others and a rotating disk device. The most recent is a review of the intel 520 series products. The performance tests are interesting, buit the reviewer seems rather unaware of the what matters for SSDs: for example the higher price of Intel SSDs is attributed to:
Measuring at the 240GB capacity size the, the Intel 520 holds a $190 price premium over the Vertex 3 240GB. We expect this gap to shrink rapidly over the next couple of months.
Intel can easily justify their price premium with their extensive validation process alone, but the accessory package for the 520 Series is more robust than many other products on the market. For starters the 520 Series products carry a full five year warranty; the industry standard these days is three years with very few companies going against the grain. Intel also includes a desktop adapter bracket making it easier to install the 2.5" form factor drive in a 3.5" drive bay. SATA power and data cables are also included with the mounting screws for installing the drive in a bracket.
Often overlooked, but never out of mind is Intel's software package that ships with their SSDs. The Intel SSD Toolbox was one of the first consumer software tools for drive optimization and still one of the best available. Inside users can see the status of their drive, make a handful of Windows optimizations, secure erase their drive and update the SSDs firmware. Intel also includes a Software Migration Tool that allows you to quickly and easily clone an existing drive.
The price premium is due mostly to Intel's peace of mind
branding, to the drive
supporting encryption, and in small part to the extra
warranty, certainly not to accessories worth a few
dollars. The software might be worth a bit more. Other flaws
in the review follow after the relevant quotes:
Today we're looking at the 240GB model that uses 256GB of Intel premium 25nm synchronous flash.
Like many other reviews the author confuses
gigabytes
with gibibytes
,
as the locial capacity is 240GB
, and the
physical capacity is not 256GB
, but 256GiB,
which are almost 275GB, of flash chips.
With the exception of the 180GB model, these are the standard SandForce user capacities that we've been looking at for years. SandForce based drives for the consumer market use a 7% overprovision instead of DRAM cache for background activity.
The 520 series have a lot more, because the logical capacity being 256GiB, which are almost 275GB, there is almost 35GB or 14% overprovisioning over 240GB. The typical 7% overprovisioning happens when the logical capacity in GB and the physical one in GiB are the same number.
Also overprovisioning is used mostly for enhancing the
endurance
and the latency
profile of the drive.
However the statement instead of DRAM cache
perplexed
me and indeed there is no dedicated DRAM chip as evident from
photographs of the board.
That's extremly perplexing as DRAM cache is very useful to
queue and rearrange logical sectors into flash
pages
and flash blocks
on writing. It
looks like that
SandForce PC-grade controllers
don't usen an external large cache for that, probably using
just their internal cache and then relying on compression and
14% (instead of 7%) overprovisioning to handle write rate
issues.
The drive is quite interesting because like most based on controllers and firmware Sandforce it is tuned for high peak performance, for example via data compression, and this explains some of the seemingly better results compared to the (much cheaper) Crucial M4 which instead performs fairly equivalently on the more realistic copy test (1, 2) or the PCMark tests from another review.
Some other interesting SSD reviews:
After writing about the near availability of large OLED displays and that LCD display production is not profitable because of overinvestment, it is not surprising to see an announcement that Samsung wants to exit the LCD business especially as:
Chinese firms have also entered the industry, a move that analysts say has made global manufacturers worry that prices may fall even further given China's low-cost base.
"New LCD production lines established by Chinese vendors are a major reason why the industry remains in an over-supply situation," Ms Hsu added.
Here the low-cost
base refers to the easy an cheap
capital available to Chinese companies, as large automated chip
and LCD panel factories employ relatively few people (and that
China at their stage of development are building automated LCD
panel factories is telling).
Presumably monitors with LCD displays will become even cheaper, and many monitors will have OLED displays within 2 years.
While reading an article on Tumblr's founder David Karp a couple of paragraph stood out as to the business:
Taking things seriously meant hiring more people, Karp thought: Tumblr had about 14 staff at the time. But then he spoke to Facebook's Mark Zuckerberg. "Mark talked me down from that. He said, 'Well, when YouTube was acquired for $1.6 billion, they had 16 employees. So don't give up on being clever.' He reminded me you could make it pretty far on smarts."
Barely a year later, though, in summer 2011, Tumblr went back to the Valley for more money, as it struggled to deal with a massive surge of users. It raised $85 million, valuing the company now at $800 million.
Tumblr now employs around 60 people. Many of the new hires are focused on turning it into a profitable business. Mark Coatney, a former Newsweek journalist, advises businesses on how to use Tumblr. He describes the platform as a "content-sharing network" which companies can use to build a new, younger audience. "It's about making users feel like they have a real connection."
What jumps out of these paragraphs is that some web
businesses are extremely scalable in terms of employees: just
add more servers. It is quite clear that web businesses are
not going to be a major source of good
jobs
, and especially not for older people.
The other interesting bit is the implication from more
money, as it struggled to deal with a massive surge of
users
which means that running costs are covered by
capital, which is no different from
YouTube
which seemed to be
mostly a bandwidth sink.
As to bandwith modern technology has made it much cheaper than
in the past, and I was astonished by another statement in the
article:
By March, Tumblr users were making 10,000 posts each hour. Karp and Arment continued consulting. The site cost about $5,000 a month to run, so they began speaking to a few angel investors and venture capitalists.
That $5,000 a month for what was already a rather popular site is not a lot really. Especially considering that most of Tumblr's blogs are entirely image based, with very little text.
Another article about the lack of outgoing links in text, this time no outgoing links from press releases:
I was reading VC investor Ben Horowitz yesterday, a post about the Future of Networking and one of his portfolio companies, Nicira Networks. There wasn’t a single link in the post.
I switched over to the official news release from Nicira: there was just one link in several pages prepared by its PR firm.
PR people know about the “link economy” because they are always pleased to see my links to their blog posts or Tweets; and I see a lot of PR people linking to stuff on Twitter and Facebook all day long– yet those lessons don’t make it into their daily work.
So why are company PR materials so link averse when their creators are so links-ago-go when it comes to promoting their own stuff?
I’ve been told that the problem is that PR firms aren’t paid to do search engine optimization (SEO), and so they don’t. Fair enough, but they could at least prepare SEO-friendly documents with links in them.
Here there is the mention of the "link economy"
where
only incoming links are rewarded,
but also a misunderstanding of the role of
PR: PR is a
euphemism for propaganda
created by
Edward Bernays.
Driving web traffic to a company's web site is promoting web
traffic, not propaganda for the company; it is marketing not
PR.
A PR company would rather let this be handled by a specialist web marketing (which is not quite the same as SEO), and probably would not want to be evaluated by their clients as to their effectiveness as to driving incoming traffic to their web sites, as that certainly is not what they specialize in.
After listening to the BTRFS interview by Chris Mason I have found a recording of a recent presentation from Oracle with some updates:
rootfilesystem in place of ext4.
copy-on-writenature of BTRFS does not require a journal. But this coincides with the best case scenario for
log-structuredfilesystems which reinforces my opinion that BTRFS is a log-structured filesystem that does not dare admit it.
In my examples of
6to4 with my ADSL gateway
there was something suboptimal, which is that packets between
6to4 hosts, both of them with
addresses within the 2002::/16 prefix, were being pointlessly
tunneled to the anycast address for the nearest
6to4 relay. This was a disappointment as my impression was
that in the sequence of commands I used:
ip tunnel add sit1 mode sit remote 192.88.99.1 ttl 64 ip link set dev sit1 mtu 1280 up IP6TO4="`ipv6calc --action conv6to4 --in ipv4 --out ipv6 192.168.1.40`" ip -6 addr add dev sit1 "$IP6TO4"/16 ip -6 route add 2000::/3 dev sit1 metric 100000
The /16 bit would result in the code implementing the mode sit tunnels to just encapsulate the IPv6 packets for which sit1 claims to be a direct network interface, and otherwise send them on to the remote address, but this obviously does not happen. So I had a look at various web pages and the canonical one from the Linux IPv6 HOWTO has a rather different setup:
ip tunnel add sit1 mode sit remote any local 192.168.1.40 ttl 64 ip link set dev sit1 mtu 1280 up IP6TO4="`ipv6calc --action conv6to4 --in ipv4 --out ipv6 192.168.1.40`" ip -6 addr add dev sit1 "$IP6TO4"/16 ip -6 route add 2000::/3 via ::192.88.99.1 metric 100000
The above sequence defines the tunnel as pure encapsulation device with any or no end point, and then routes IPv6 packets to an IPv4 address of the nearest 6to4 relay wrapped as an IPv6 address. This does allow direct 6to4 to 6to4 host packet traffic, but I regard the routing of IPv6 packets to an IPv4 address as rather distasteful.
Looking back it seems that the mode sit tunnel code merely encapsulates if no specific remote tunnel endpoint is specified, and otherwise tunnels as well if it is specified. Which suggests that the better approach is to use two mode sit virtual interfaces, one for direct 6to4 with 6to4 node traffic, and the other for traffic with native IPv6 nodes that needs to be relayed by an IPv6 router:
IP6TO4="`ipv6calc --action conv6to4 --in ipv4 --out ipv6 192.168.1.40`" ip tunnel add 6to4net mode sit local 192.168.1.40 remote any ttl 64 ip link set dev 6to4net mtu 1280 up ip -6 addr add dev 6to4net "$IP6TO4"/16 ip tunnel add 6to4rly mode sit local 192.168.1.40 remote 192.88.99.1 ttl 48 ip link set dev 6to4rly mtu 1280 up ip -6 addr add dev 6to4rly "$IP6TO4"/128 ip -6 route add 2000::/3 dev 6to4rly metric 100000
With that setup there are two mode sit devices, one with remote any that will only encapsulate packets, the other that will encapsulate packets and tunnel them to 192.88.99.1; the first has a more specific route such that it will only be used for other 6to4 nodes with prefix 2002::/16, and the other has a more generic route to all other globally routable addresses.
While reading
an article about infographics
I felt again that they are a terrible idea, and a betrayal of
the idea of hypertext, because they contains a lot of text
rendered as if it were an image:
In straddling the visual/verbal divide, infographics like this map first gain entrance by using the succinct allure of imagery, but then linger in our imagination by nurturing our hunger for cultural narration.
The disadavantage of straddling the visual/verbal divide
is that on the hypertext web, any text embedded in an image
becomes invisible to text-based tools like search engines.
It is the reductionism of the medium that is downside, while the article argues instead that it is the small size of the infographic that fosters a level of reductionism of the narrative:
Reductionism itself is not inherently bad — in fact, it’s an essential part of any kind of synthesis, be it mapmaking, journalism, particle physics, or statistical analysis. The problem arises when the act of reduction — in this case rendering data into an aesthetically elegant graphic — actually begins to unintentionally oversimplify, obscure, or warp the author’s intended narrative, instead of bringing it into focus.
The article I was reading is so centered on the content and narrative issue that it praises the RISING AND RECEDING infographic for its effectiveness at delivering content:
Yet this infographic succeeds because the collective collation and bare presentation of this data against the backdrop of a recession offers us a fleeting peek into intimate moments during hard times, albeit intimacy that is repeated across millions of households.
Felton knows that to convey a trend most effectively, you must leave room for a dual narrative—the reader needs to process the information on both a public level (“Births are down?”) and private level (“Could we afford a child right now?”).
Even if the meaning of the content is largely delivered by text that is the overwhelming majority of area of the image.
The reductionism here is that the hypertext web is reduced to a delivery channel for leaflets, for what are in effect scans of what would be printed pages.
In effect the article applies only to infographics in a printed medium, when instead they are very popular on the web too, and ever more as they look cool and engaging.
Unfortunately on the web not only that text in the infographic is invisible to hypertext tools, it is devoid of any hypertextual marking, such as hyperlinks, or simple annotations. Put another way, it is a sink of information, not a spring, as it is contextless.
At times I wonder whether this is is intentional, as text without outgoing hyperlinks, sinks instead of springs, is what gets rewarded by Google's business model but I don't think that explains entirely the popularity of information sinks in the form of text within image or Flash embeddings. I suspect that a large part of it is simply the conservativism of graphics designers who just think about media as simulating sheets of paper.
Note: there are sites like ScribD that deliberately use Flash or images to make text less accessible to text-based tools (such as copy-and-paste), but that's I think in a different category.
Since the version of the X window system
server that I am using has a fatal bug that only happens when
large characters are rendered in non-antialiased fashion, I have
very reluctantly switched for the time being to antialiased
text rendering, even if I dislike that as
previously noted
antialiased text seem to be significantly fatter/bolder
and fuzzier.
However I am currently using window background colour to indicate the type of window, in particular with terminal windows, and while most of the time the background is some light off-shite shade, I occasionally use a black background, and in the latter case I was astonished to see that anti-aliased text looks much better with a black background.
Since Konsole from the KDE SC version 4 makes it easy to change both background colour and toggle anti-aliasing, I could compare some cases and indeed anti-aliasing seems to work a lot better on dark backgrounds.
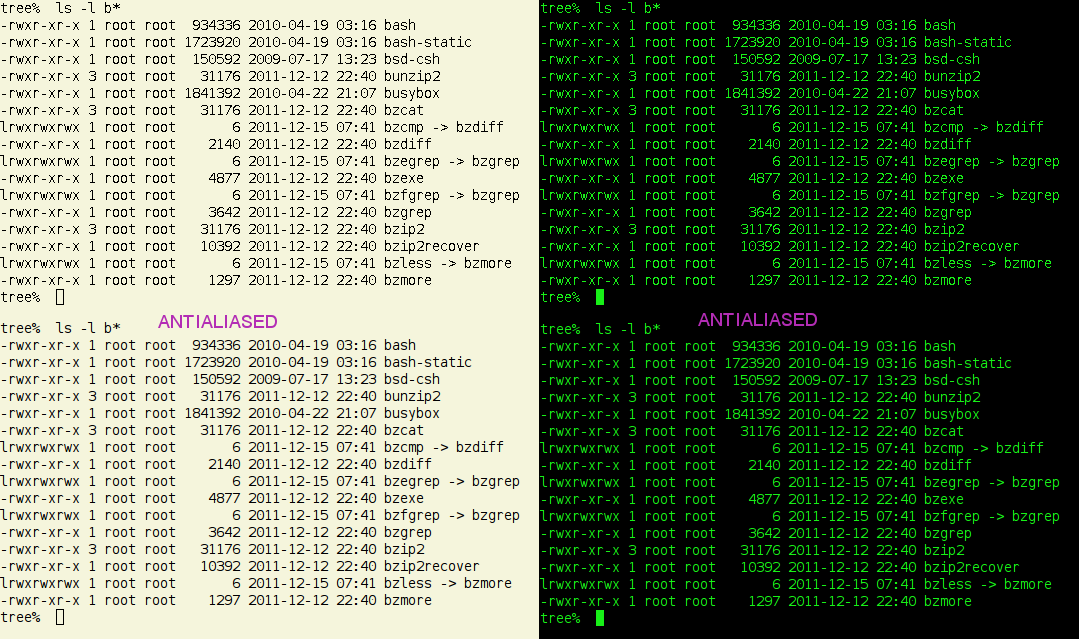
I have pasted together four cases in this snapshot (which must be seen in 1:1 zoom) to illustrate. The examples all involve the DejaVu Sans Mono font, which renders fairly well without anti-aliasing (but not as well as fonts designed for bitmap rendering), and the top row is text without anti-aliasing and the bottom row is with anti-aliasing, and columns with different backgrounds. It is pretty obvious how much bolder and fuzzier anti-aliased text is on a light background, but also that with a black background the anti-aliased version does not seem much worse than the other, except perhaps a bit thinner and less bright.
Obviously the gray fringe used to anti-alias text looks very different whether the surrounding background is light or dark, but I am surprised at how large the difference is. Now I understand that dark backgrounds must be much more popular than I thought, and so must be anti-aliasing, also because the bug that prompted me to switch temporarily to anti-aliasing only happens without it, and was reported pretty late.
Overall I think that anti-aliasing might be a good idea only for the case for which it was originally invented, that is 240-300DPI printers, where the character features are several pixels thick, and an extra border of gray single pixels does not nearly double its apparent thickness, but does indeed smooth out the outline.
Unfortunately current display for the most part have regrettably low DPI and therefore normal-size (10 point) character features are one-pixel thick. Sure that one pixel thick lines look quite ragged if oblique or curve, but anti-aliasing can only fix that by nearly doubling the thickness of those linesm, at least on light backgrounds. Perhaps the anti-aliasing algorithm should use much lighter grays on light backgrounds, and anti-aliasing would look better just as it does with the darker greys on dark backgrounds.
snapshotsand
integrity. This seems consistent with the original BTRFS motivation to be a Linux based alternative to ZFS, which could not be ported to Linux because of licensing conflicts.
copy-on-writelogic, and because of this it was the default filesystem for the Meego GNU/Linux distribution for tablets and smartphones. As to this copy-on-write, like for log-structure filesystems, that works well on flash MTDs which expose the flash memory to the filesystem, but I am not sure that they are much of benefit with flash SSDs, which have on top of an MTD a FTL firmware that simulates a traditional disk unit using itself a copy-on-write logic.
It is not clear to me what is Oracle doing in the filesystem area, because they started developing OCFS2 which is very popular with Oracle DBMS customers and seems to be pretty well designed and implemented, even with a traditional structure, then they sponsored the development of BTRFS because ZFS could not be ported to Linux, and seemed to have scalability and reliability aimed at enterprise users, and then Oracle bought Sun Microsystems which gave them ownership of ZFS but they did not change the license and continued developing BTRFS.
If there is a filesystem that should go into an Enterprise Linux distribution as the main or default one that should be OCFS2, as it is far more mature and better tested in the field, and simpler, and supports very well the sort of applications that Oreacle themselves sell.
While I am still quite impressed by how good is my current LCD monitor all current monitors with an LCD display have the substantial problem that they display is transmissive and a quite opaque sandwich of many layers, thus requiring powerful backlights, and with often some difficulties with dark tones, and issues with viewing angles, as the LCD transmissive layer is not equally transparent in all directions.
OLED displays are instead emissive, and can be built as a single layer too, like plasma display which results in much better contrast, viewing angle and color fidelity. It can also result in higher power consumption when displaying mostly light areas, which has induced some smartphone manufacturers to developed mostly dark user interfaces and someone to create a mostly dark web search form.
My camera
and many recent smartphones
have OLED
screens, which means that they have become manufacturable,
even if in small sizes. But I have just seen
an announcement
that large 55in OLED displays are
being manufactured for television sets. Smaller displays for
computer monitors cannot be far behind hopefully.
It is also interesting to note that the manufacturer is making smaller losses on their LCD products.
I have been double checking my home
IPv6 setup in which my laptop and
my desktop have independent IPv6-in-UDP
tunnels
provided by
SixXS
and my web site (the one that you are reading) relies on
6to4
encapsulation and automatic routing, and I wondered whether my
new Technicolor (previously called
Thomson)
TG585v7
ADSL gateway
would be transparent to it. My previous ADLS gateway, a
Draytek
Vigor 2800
seemed to drop all IP packets with unusual content type, and
6to4 packets have type 41, for IPv6-in-IPv4 encapsulation.
It not only passes through type 41 packets, it actually
performs
NAT
on both the IPv4 and the IPv6 headers inside the packet:
IP 192.168.1.40 > 192.88.99.1: IP6 2002:c0a8:128:: > 2002:4a32:3587::: ICMP6, echo request, seq 362, length 64 IP 192.88.99.1 > 192.168.1.40: IP6 2002:4a32:3587:: > 2002:c0a8:128::: ICMP6, echo reply, seq 362, length 64
IP 192.88.99.1 > 74.50.53.135: IP6 2002:57c2:6328:: > 2002:4a32:3587::: ICMP6, echo request, seq 326, length 64 IP 74.50.53.135 > 192.88.99.1: IP6 2002:4a32:3587:: > 2002:57c2:6328::: ICMP6, echo reply, seq 326, length 64
# ipv6calc --action conv6to4 --in ipv6 --out ipv4 2002:c0a8:128:: 192.168.1.40 # ipv6calc --action conv6to4 --in ipv6 --out ipv4 2002:57c2:6328:: 87.194.99.40 # ipv6calc --action conv6to4 --in ipv6 --out ipv4 2002:4a32:3587:: 74.50.53.135
In the above 192.168.1.40 is the internal IPv4
address of the sending node, 87.194.99.40 is the
external IPv4 address of the gateway, 74.50.53.135 is
the IPv4 address of the destination node, and
192.88.99.1 is the well-known
anycast
address of the nearest 6to4 relay.
Since 6to4 NAT can only map onto the external address of the gateway the internal address of the sender, only one internal address can be mapped that way. In theory this means that any number of internal nodes can use 6to4 as long as they do it at different times, but that is an untenable situation.
What is possible is to declare one of the internal nodes as the internal network's IPv6 default router, and get it to be the 6to4 node, and assign to the other nodes IPv6 addresses within the /48 6to4 subnet, and that seems to work, as both the router and another internal node:
IP 192.168.1.40 > 192.88.99.1: IP6 2002:c0a8:128:: > 2002:4a32:3587::: ICMP6, echo request, seq 16, length 64 IP 192.168.1.40 > 192.88.99.1: IP6 2002:c0a8:128::22 > 2002:4a32:3587::: ICMP6, echo request, seq 9, length 64 IP 192.88.99.1 > 192.168.1.40: IP6 2002:4a32:3587:: > 2002:c0a8:128::: ICMP6, echo reply, seq 16, length 64 IP 192.88.99.1 > 192.168.1.40: IP6 2002:4a32:3587:: > 2002:c0a8:128::22: ICMP6, echo reply, seq 9, length 64
That the TG585v7 both allows IPv4 protocol 41 packets through, and even NATs their addresses, means that joining the IPv6 Internet is very easy, as no consideration need to be given to the external address of the ADSL gateway, or to instructing it to/from which node forward protocol packets, as long as:
Also note that the gateway's NAT, being dynamic, works in the incoming (external to internal) only if it has been setup by some previous outgoing packets.
How to setup an internal node for 6to4 is described in many places on the Web, but one Linux set of commands I use is:
ip tunnel add sit1 mode sit remote 192.88.99.1 ttl 64 ip link set dev sit1 mtu 1280 up IP6TO4="`ipv6calc --action conv6to4 --in ipv4 --out ipv6 192.168.1.40`" ip -6 addr add dev sit1 "$IP6TO4"/16 ip -6 route add 2000::/3 dev sit1 metric 100000
I have been reading with great interest a detailed review of an enteprise grade flash SSD which is a Samsung 400GB SM825 of the same generation as a similar consumer grade flash SSD the PM830, which invites comparison, and the main differences are:
over-provisioning.
The massively increased over-provisioning and the use of eMLC
flash chips with higher erase cycles result in much higher
endurance
of 3,500TB for the enteprise 200GB unit versus around 60TB for
the consumer 256GB unit. This means that it can support a much
higher number of updates, and maintain low latency writes during
a long sequence of updates, but also that its performance will
not decrease for many years.
The massive capacitors are there most likely to ensure that the data in the flash chips can be refreshed for years, instead of fading after some months if unpowered.
It is quite remarkable that measured peak rates on the SM825 are at (read:write) 250:210MB/s only roughly half those of 510:385MB/s of the PM830. Because the two products have the same number of flash chips and dies of the same type, which gives them the same base bandwidth. One possibility is that the transfer rates have been deliberately limited so as to give the unit a consistent performance across its lifetime, instead of much higher performance when it is new and clean and slowing down after it has been used for a while.
It is also remarkable that for both drives the write rates are almost as high as the read rates, which is atypical for flash SSDs, and that they are particularly similar for the enterprise grade drive reinforces my impression that transfer rates for it are deliveberately reduced.
I have some WD disk drives, some of them from their Green product line.
Just like most recent storage devices these disk drives are complex systems with lots of software and subject to a constant updates, and they are designed for low cost and low power, which was not a common niche. As a result it turns out that they have had a number of issues:
In order to conserve power the WD Green drives are programmed to go into various degrees of sleep modes, and tis involves first retracting the pickup arms, and then stop rotating the disks assembly. Initially this was set to happen way too often:
So after one of my WD20EADS 2tb Green drives failed I came across some research on other forums that pointed out that one of the features of the Western Digital green drives is "Intellipark".
What is Intellipark you ask? Well its a "feature" on these green drives that parks the head every x seconds of inactivity, the default being 8 seconds for both read & write.
This causes on semi-active systems way too many load-unload or start-stop cycles, beyong the number for which the drive is rate (as well as impacting performance).
This issue had already been noticed before with laptop drives which are also usually designed for low power and low cost.
The solution is to change either the default timeout in the drive itself or to change the timeout when the drive gets activated, usually with hdparm.
WD Green drives are targeted at consumers, and WD have
decided to disable their
ERC
as part of their market segmentation
strategy.
This means that WD Green drives will usually freeze for around 1-2 minutes doing retries when errors happen.
There is no solution.
In order to pack more data by reducing the percentage of tracks devoted to metadata, many recent disk drives have 4KiB hardware sectors, and WD Green drives have been among the first. Because of the inability of many older operating system kernels to deal with 4KiB sectors, they simulate 512B sectors.
Despite that they do not work well with the common MBR partitioning scheme from PC-DOS, as that aligns some partitions to 63×512 bytes, causing read-modify-write on all writes.
The WD Green drives can also offset all sector addresses by 1 so the physical offset of those partitions is 64×512 which is a multiple of 4KiB, but this causes problems with partitions which are better aligned.
At least most WD Green models report a 512B logical sector size and a 4KiB physical sector size, unlike many drives that do not provide this information or report a 512B physical sector size when it is larger.
The solution is to ensure that all filetrees within a partition start and are long a multiple of 4KiB, or ideally even up to 1-4MiB or 1GiB, using fdisk in sector mode or parted or GPT partitioning, or no partitions.
Even for popular standards like PATA and SATA there are many questionable or buggy implementations, and most drives contain workarounds for the bugs of host adapter chipsets, and the same for operating system issues.
In more benign cases operations simply time out as the drive takes time to restart, and in the case of some chipsets (notably JMicron ones) with which CRC errors happen during data transfers, some operatings systems reduce the speed of transfers to 1-4MiB/s when the failed operation can be simply retried.
One crazy solution is to tell the operating system to ignore data transfer errors, but at least for many versions of MS-Windows there is a fix in the error recovery logic of the kernel:
An alternate, less-aggressive policy is implemented to reduce the transfer mode (from faster to slower DMA modes, and then eventually to PIO mode) on time-out and CRC errors. The existing behavior is that the IDE/ATAPI Port driver (Atapi.sys) reduces the transfer mode after any 6 cumulative time-out or CRC errors. When the new policy is implemented by this fix, Atapi.sys reduces the transfer mode only after 6 consecutive time-out or CRC errors. This new policy is implemented only if the registry value that is described later in this article is present.
The solution is to ensure that errors, especially CRC
errors, do not happen by choosing known-working chipsets
and good quality cables, and ensuring that the OS kernel
uses the less-aggressive
policy in handling them
when they occur.
The drives from several other manufacturers have some or most of the same issues, but the WD Green series seems to have had a particular run of them, again probably because of their less traditional aims.
Just reading a somewhat recent
presentation
on petascale
file systems. It has some
useful taxonomy and comparison of features, and examples
of large scale storage systems.
Found an interesting list of YouTube videos of potential interest to geeks: http://lwn.net/Articles/476498/ which the authors says is converting and reuploading:
I like to download various Linux/FLOSS conference talks from YouTube, convert them to webm and then post them to archive.org (assuming the licensing allows it).
After discussing how inappropriate it is to have a RAID6 set with 4 drives it may be useful to note here most of my objections to the common use of RAID6 sets, often quite large.
The first point is terminological: some people misuses RAID6
to indicate any arrangement with two or
more parity blocks per stripe, whether these are are bit,
byte, block parallel stripes, and the storage devices are
staggered (like RAID5) or not (RAID2, RAID3, RAID4).
The popularity of RAID6, or in general two or more parity blocks per stripe, is easy to understand: it is a structure that seemingly offers something for nothing, that is:
Dual parity is therefore the salesman and manager's obvious choice, or the sysadm's preferred solution to achieve hero status, just like VLANs and centralized services.
Unfortunately dual parity sets is one of those great ideas that isn't great, and should be avoided in nearly all cases because:
These and other arguments are also exposed by the BAARF site.
However RAID6 has a very large advantage
:
it will look good up-front, if the filetree to be
stored on top of the RAID6 set starts small and the load on it
starts low. In that case for a significant initial period the
RAID6 set will be significantly oversized above needs and
after the usual early mortality issues it will look quite
reliable, thus apparently validating the choice of RAID6, even
of wide RAID6 sets.
But as the filetree fills up (and also become more scattered) and the load increases there will start to be significant performance and reliability problems. Also when a filetree becomes larger even if the average load on it stays small (for example if most of the data is very rarely accessed) the peak load on its storage will necessarily go up, because of whole-filetree operations like file system checking after crashes, indexing, and backup.
So the main advantage of RAID6 is that it will look
cheap and scalable and reliable while eventually scaling
terribly and expensively and
unreliably. But often is a problem for someone else (and it
turns out that I have been the someone else in some cases,
which may be one reason why I wrote this note).
I was reading an interesting interview about parallel computing and I found it quite comical at times, especially this:
Until 1988, when I wrote the paper about reevaluating Amdahl's law, parallel processing was simply an academic curiosity that was viewed somewhat derisively by the big computer companies. When my team at Sandia -- thank you, Gary Montry and Bob Benner -- demonstrated that you could really get huge speedups on huge numbers of processors, it finally got people to change their minds.
I am still amused by people out there gnashing their teeth about how to get performance out of multicore chips. Depending on what school they went to, they might think Amdahl proved that parallel processing will never work, or on the other hand, they might have read my paper and now have a different perception of how we use bigger computers to solve bigger problems, and not to solve the problems that fit existing computers. If that's what I wind up being remembered for, I have no complaints.
The delusionally boastful statement above is based on a confusion between parallel processing and parallel programming.
The parallel programming problem is not solved yet, either to scalable performance or as to avoiding time dependent mistakes.
But parallel processing does not require much in the
way of parallel programming, such as scheduling or
synchronization, in a narrow set of cases which are however
extremely important practically, and I can't imagine that
someone ever thought that Amdahl's law applied to them: the
so-called
embarassingly parallel
algorithms.
Embarassingly parallel algorithms are popular because many real-world related applications use them, because several aspects of the real-world are very repetitive with very limited interaction among the repetitions.
This was not a new or even interesting argument in 1988.
Thinking about LCD panels reminded me that the LCD monitors I briefly reviewed some time ago are somewhat old models, and newer models have been introduced, and in particular with IPS or PVA /MVA panels which are often significantly better than the alternatives.
As usual the PRAD and TFT Central sites have good information and reviews of many good monitors, and I also have read several other reviews, as I like to keep somewhat current on which monitors are likely to be good, and my current list includes:
Having mentioned OCFS2 and DRBD it occurred to me I intended to add something to my previous note about types of clusters being resilience or speed oriented, either by redundancy or by parallelism. More specifically redundancy and parallelism can take several forms.
Redundancy for example can be full, where every type of member of the cluster is replicated, or there can be a shared arrangement, where some less critical members are shared, and some more critical ones are replicated. In the shared case there are two common cases:
front-endmembers are replicated, and the
back-endis shared, for example replicated web servers sharing a storage system.
back-endmembers can be replicated, and the
front-endmembers can be shared, for example in the case of system with storage layer on a DRBD mirror pair.
The replicated members of a single type can also be:
active(
hot), where an member is being used all the time, which implies synchronization of their state among all.
passive(
warm) where an member is not in use but can be put in use at any one time, which implies synchronization of state from active ones.
standby(
cold) where an member is not in use and needs some preparation before it can be put in use. Of these there are two subtypes, those that
onlinebeing connected to the cluster(of course active and passive members are always online), and need only status synchronization from an active or passive one, and those that are
offlineas they are fully disconnected from the cluster (typically on a shelf somewhere).
Parallel clusters can also be of two types:
Of course all the terms used above have been confusingly used
to mean slightly different things, so some people use online
to mean active
, but
the concepts are always the same.
Filesystems
(and storage layers) can
belong to any of these categories (and there are some further
subcategories), and in particular tend be either based on
redundancy or parallelism. For some common examples:
metadataserver) and replicated back-ends (the data servers).
Quite naturally a cluster could be built from a mix of these structural choices, both in the same layer or in different layers: for example redundancy in the storage layer and parallelism in the filesystem layer.

{kind=link}