-
 Section menu
Section menu
This document contains only my personal opinions and calls of judgement, and where any comment is made as to the quality of anybody's work, the comment is an opinion, in my judgement.
[file this blog page at: digg del.icio.us Technorati]
I have previously mentioned the issue of
IOPS-per-TB
and the related requirement from CERN for disk storage systems
to deliver
at least 18MB/s of parallel read-write per TB
(where at least
means worst-case
and
parallel
means interleaved
, at least on a single
disk) and I was recently astonished to hear someone comment
that is pretty easily satisfied given that hard disks have a
transfer rate of 150MB/s, when I mentioned that disk larger
than 1TB were not likely to achieve that, especially 4-10TB
archival disks.
Then I noticed that person was using a MacBook Pro with a very high transfer rate flash SSD with very high IOPS rates and I suspect that detached him from a keen awareness of the performance envelope of rotating disk drives.
Part of the performance envelope of typical contemporary disk drives is that in purely sequential transfers they can do up to 150MB/s on the outer cylinders and up to 80MB/s on the inner cylinders (flash SSDs don't have this difference), and that average random positioning times are around 12ms (flash SSDs have small fractions of a millisecond at least fom reading).
Simultaneous read-write rates of at least 18MB/s (not per TB) require at least one random positioning per transfer, and at 80MB/s it takes around 12ms to transfer 1MB; therefore reading-writing sequentially two parallel streams with 1MB blocks, which are huge, gives around 25ms per block, for a total of 40MB/s, and it takes a read/write transfer size of at least 320KB to achieve at least 18MB/s, in pretty much optimal conditions, and let's say 0.5MB transfers to be have some margin for variability.
It then takes 3MB transfers to deliver 60MB/s parallel read-write suitable for a 3TB disk, and disks of 4TB cannot deliver 80MB/s except in purely single stream stream mode, that is in practice no disk larger than 3TB can deliver 18MB/s parallel read-write.
Note: That is a 1TB disk capable of 80 random IOPS needs 0.5MB transfers to deliver 18MB/s of parallel read-writes. Put another way, with 64KB transfers a storage unit needs at least 400 random IOPS per TB to deliver 18MB/s of parallel read-writes per TB, and no single disk drive can do that. With 16KB transfers at least 1,700 random IOPS are needed.
Not many applications can afford to read or write with transfers as large as 0.5MB and 3MB. And it is not just the application that must use those transfer sizes: the data on disk must be contiguous for at least the length of the transfer size.
Large transfer sizes also have a very big downside: starting latency for every transfer is driven by the size of the previous transfer, and completion latency by that of the current transfer. A 0.5MB transfer take 18ms to complete, and on a busy 1TB disk that means each transfer not only has a completion latency of 18ms, but also starts at least 18ms after being issued. An IO latency of 18ms is pretty huge. On a 3TB disk with 3MB blocks completion latency goes up to 50ms.
The cause of large latency is that random positioning has a latency of 12ms, and to amortize the cost of that one has to choose large IO sizes, and those add to the latency as it takes even more time to transfer larger blocks. It is possible to mitigate the latency to completion of the current transfer by delivering the large transfers incrementally as a sequence of smaller blocks, but the latency to starting the next transfer still is the full size of the previous transfer.
Also transfer sizes of 0.5MB per operation on a 1TB disk are quite challenging also because on a busy system many IO operations, in particular metadata and logging operations, use much smaller transfer sizes, and in particular opening a file requires usually at least one random short transfer.
It depends on workload and in particular on average IO operation size and average contiguity on disk, but sustaining 18MB parallel read-write per TB of capacity, that requires contiguous transfers of at least 0.5MB, seem to me quite a challenge even on 1TB drives.
Note: the above contains some simple arithmetic, but some familiarity with watching actual disk based storage systems should give a very solid intuitive understanding that 18MB/s parallel worst-case read-write per TB is a pretty demanding goal. I suspect that so many people now have desktops and laptops with flash SSDs that intuitive understanding is harder to develop.
As
previously noted
the IOPS-per-TB issue is per TB of data actually present,
rather than of available capacity. An approach that seems astute
to some people is to show-off the IO
rate and low cost of a storage system using large cheap-per-TB
disk drives when it is still far from full, for example when
each drive has less than 1TB of data on it, even if its
capacity is 4-10TB, because that 1TB of actual data:
short-strokingrandom accesses so that they take rather less than 12ms on average.
In effect in the beginning 4-10TB drives are behaving as if
they were particularly fast 1TB drives. But when they fill up
their observed average speed will fall to 1/4 or less than
that of a when they had only 1TB of data. I have seen that
happen quite a few times on storage systems setup by astute
people.
Recent news are that copyright violations of any extent are now treated like theft in the UK, having become a criminal instead of civil matter:
it's now possible for copyright holders to pursue criminal cases for an infringer of any size
This reminded me of being asked some time ago to comment on some employment contract terms that included vesting all copyright in any works created by the employee during that contract to the employer. My opinion as a non-lawyer is that was intended to mean that every single email, photo, letter, blog posts, made by that individual belonged solely to their employers. This included of course every personal one, including family photos, private letters, public blog posts, etc.; my opinion as a non-lawyer is that whether that was enforceable was more likely than not, but also that it would be extremely expensive for an individual to contest that in court. If it were enforceable two consequences might happen in my opinion:
Now in the past such consequences in my opinion would be fairly small, except for the cost of a court case, because if the matter was civil the employer would have to prove and quantify damages, and I reckon that any claim to damages for giving an employee's relatives a photo of say their family would be laughed out of court. But I reckon that the employee could still be subject to summary dismissal for contract violation.
But my impression is that if copyright violation of any type is a criminal offense, like stealing a sandwich from a shop is theft regardless of the amount involved, then an employer making employer-unautorized copies of a private email she has written by sending that email to her parents and siblings might well be punished with a jail sentence.
If that were a consequence, employers would have not just have a way to terminate employment for breach on contract any employee who sent a personal email, photo, letter, published a blog post without authorization, but also to prosecute and perhaps to jail them. That would be a very powerful way to put pressure on employees. Any claim that such clauses would never be used in that way is ridiculous: lawyers are as a rule required to make full use of any legal advantage they can find, and they are not shy.
As to that, the same employement terms contained fairly extreme non-compete clauses, even for a low-end back-office clerical job, not an executive or research job. My impression as a non-lawyer is that in the UK they are not enforceable; but if the employer were determined to bring suit, it would be very expensive to defend against it. In some jurisdictions even extreme non-compete clauses are enforceable.
Update 170611: Indeed I have recently read an article reporting a case where they were enforced, probably to as an example to others:
How Noncompete Clauses Keep Workers Locked In
Restrictions once limited to executives are now spreading across the labor landscape — making it tougher for Americans to get a raise.
As I was trying out some GUI file managers (notably KDE's Dolphin and Konqueror) to rename and move files inside a directory in which I had let too many file name entries accumulate I noticed that the option to hard link a file was missing. That is oddd as hard linking is a pretty fundamental UNIX operation and very useful to have different names refer to the same file, so I did a web search and discovered a relevant bug report and this comment in it:
I must say that I'm strongly against such a feature. The entry "Clone" (or whatever it's called) will be useful for only a few, but confuse ~99% of all users.
Now those who like to create hard links will say "Just add an option for it", but if we add options for every little thing that a few people consider useful (please believe me, there are *lots* of such things),
The comment reveals that the
microsoftization
of the Linux ecosystem continues, and how deep it has
become.
Note: an irony here is that they allow
symbolic linking, but even if symbolic links resemble the
shortcuts
of MS-Windows they are quite
different in semantics, risking more confusion.
Sort of like expected the dired module in EMACS has hard-linking, and Midnight Commander has it too. Fortunately. But I liked the ability to rename files inline. I will use writable dired mode instead.
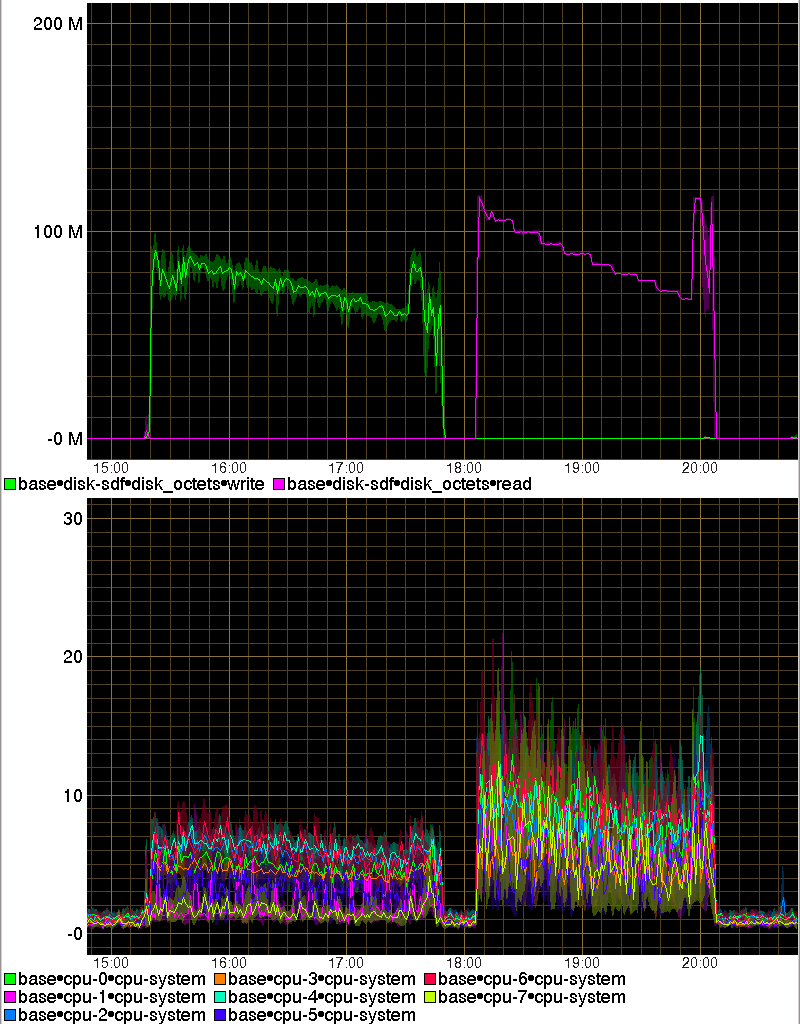
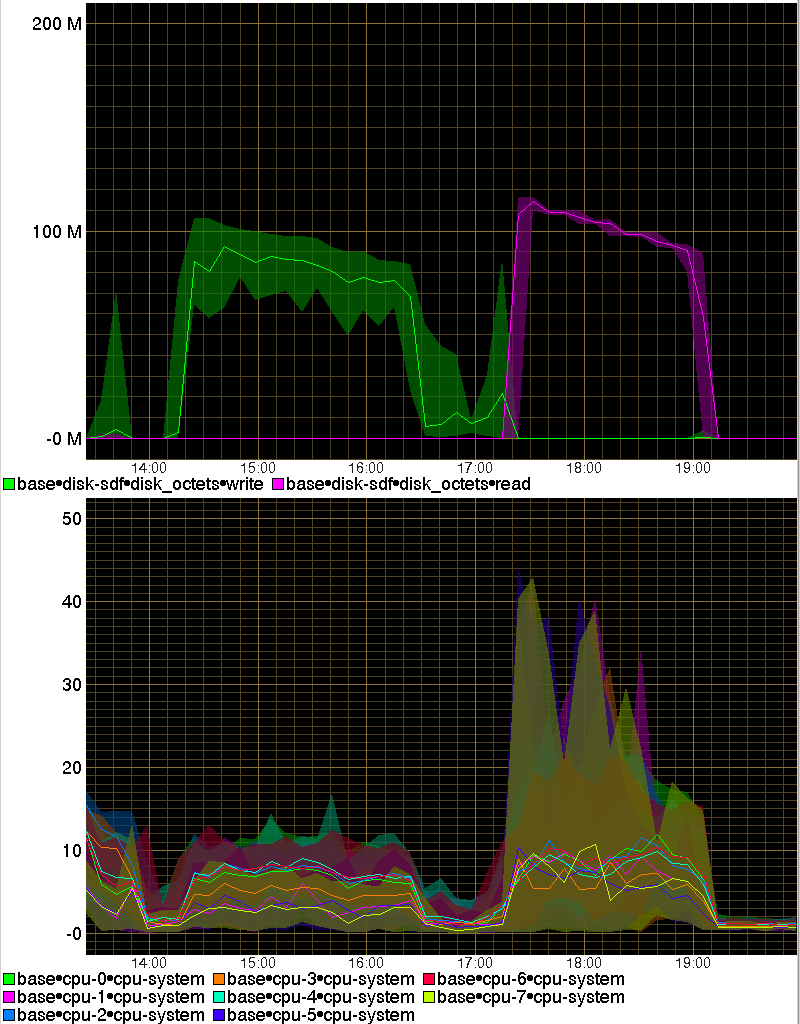
After looking again at the graph showing that the CPU temperature of my laptop being strictly dependent on CPU load I checked my laptop's collectd graphs and that was confirmed. Which was highly suspicious as at some point the fan should start operating and cool the CPU.
So I did a minimal amount of cooling conduit cleanup: first I hit the relevant area with a rubber mallet to shake it a bit (dust tends to clump) and then I blew hard through it, and used a hoover to aspire it out. The result is quite amazing, ands it is that now without much exception the CPU temperature is fixed pretty much at 50C except during periods of very high load:

The difference is large, and I suspect that for some reason my laptop's CPU must have been stuck. Looking at the collectd graph that must have happened more than a year ago. Also I have cleaned the inflow dust filter grilles of my excellent NZXT H230 desktop case and that by itself has got the temperature of the hard disks in it to drop by on average 3C (from an already rather low level):

The recent story of the leaking of the NSA hoard of tools exploiting MS-Windows bugs and the resulting use of that for a ransom-ware project is fairly amusing as well as some comments on it.
My impression is that it is not such a big deal: I would
expect every major black-hat
group to have
a long library of exploits
, even packaged
as
kits
some of them resulting from accidental bugs in various
software parts, and some of them well designed deliberate bugs
created by the people the black-hat teams quite likely
have infiltrated
in major software companies and groups. The NSA hoard is
probably one of several they have, and likely one of the least
valuable.
Note: it is not a surprise that someone at Microsoft complained that the NSA had not reported the bug but most likely several other black-hat groups knew of the same bug and nobody reported it either. Because the job of black-hat groups is to use the bugs, not get them fixed, and accidental bugs (if that was an accidental bug) are particularly convenient to keep in a list because the deliberate bugs are too precious to use except in difficult cases.
Therefore one particular exploit kit is not that important in
the black-hat world. Also because basic exploit kits relying
on accidental bugs are in general not that important, because
they are meant to be used towards generic targets: they are in
general of value only statistically, that is against generic
masses of target systems, a certain percentage of which will
have some exploitable bug. Because of their genericity they
are useful for gaining access from outside
to inside
systems, that is from
the Internet
to some private system.
Therefore as in the current situation their usefulness is for
implanting on the target systems ransom-ware
or spam-bot
modules, rather than steal
information or money directly. Also they tend to be a bit too
obvious, so involving a high risk of discovery.
What is more worrying for people in my line of work that
involves protecting server systems, are the tools involved in
targeted
black-hat
activities, against specific sites or people. These tools are
invariably based on some form of access from the inside to the
outside, from a private system that has been compromised to
the general internet. The difficulty of course is how to
compromise a private system, and that is why both the relevant
techniques are used for targeted access and also in general
can or should be used for targeted access.
Note: some over-entusiastic person kept
asking me for pointers to exploit kits for accessing bank
computers and taking money from them. That is a really stupid
idea because outside-to-inside exploit kits are the wrong
approach, and bank computers that handle money flows are a
harder target than most even for targeted access tools.
That's why black-hat organizations use exploit kits for
generic personal computers hoping for statistical
effectiveness (even a small percentage of exploited systems
can be profitable) as to opportunities for installation of
ransom-ware or spam-ware. It is rather bank executives who misdirect
large flows of money quite legally
by doing dodgy deals and become rich from the related
bonuses. Paraphrasing what someone wise said, robbing a bank
is much harder than embezzling from it.
All these techniques are exact replicas of traditional
spy techniques
(nihil novum sub soli
)
based on planting something and someone inside, and the way to
achieve that is to have someone or something outside that gets
taken inside.
Note: for some examples of a discussion
of what can be done to add deliberate bugs
as to hardware design there is a nice presentation by Bunnie Huang,
Impedance Matching Expectations Between RISC-V and the Open Hardware Community
given on 2017-05-10 at 11:00am at the
6th RISC-V workshop.
Edward Snowden has published a catalogue of techniques and hardware devices that the NSA had available several years ago, typically based on communication devices that are difficult to see and detect and are planted into the target systems. These are planted into the system before the system is delivered inside, or by someone who takes them from outside to inside. Among those planted outside before the system is taken inside are the software bugs planted by agents of a black-hat organization at the source, while working for a hardware or software company.
These techniques and hardware devices rely on a large budget and protection from a state entity to be effective, but that's at available to the NSA and many other black-hat groups, both government sponsored or independent. Given that I think that defending against a targeted operation by a group at that level is practically impossible for almost any private individual or commercial organization, and that it is already extremely difficult to detect such operations.
In practice the best choice is to avoid being the target of
such a high-budget operation. Since these operations are
risky and expensive, they are only justified against
particularly valuable targets. Not being a valuable target is
in general a very desirable situation because typically
security budgets in profit
(in a wide
sense) oriented organizations are massively undersized, even
at valuable targets, as they are costs to be incurred without
the promise of an immediate profit
, just
the possibility of minimising the costs of an attack maybe a
long while later. Sometimes I commiserate the system
administrators in organizations that handle money. I prefer to
stick to research data (which is usually worthless without the
accompanying metadata, such as the details of the experimental
conditions), or public/publishable data like web content, for
example advertising content.
Some user on
IRC
reported a very inconvenient situation: for some reason a
disk to be accessed from Linux had
a malformed partition table
that crashed
the kernel code that attempted to parse it. It would have been
very easy to clear the relevant area of the disk, but that
could not be done because by default Linux attempts to read
the partition table as soon as a disk is connected.
This was obviously one of the many cases of violation of
sensible practices in Linux design due to an excessive desire
for automagic
, and I could relate to it as
I had to maintain system which used unpartitioned disks and
printed on every boot a lot of spurious error messages about
malformed partition tables (without crashing at least).
It is easy to verify that in the Linux kernel the
rescan_partitions
function is invoked unconditionally by the
__blkdev_get
function, and therefore it is impossible to avoid an attempt
to find and parse a partition table. Ten years ago
a simple patch was proposed
to avoid scanning for a partition table at boot time, but it
was not adopted.
So I thought about a workaround that ought
to work: to use the boot parameter that tells the kernel that
a specific block device has a given partition table using the
boot kernel parameter
blkdevparts.
Since the code in rescan_partitions stops looking
for a volume label when the first match is found this ought to
work. Even if in the
check_part
table, which is organized alphabetically, the
cmdline_partition section follows several checks
for some variants of the Acorn
volume label type, which should not be mostly a problem.
The overall issue is that because of the ever deepening
microsoftization
of GNU/Linux culture improper designs are made to be as
automagic as possible: in this case the improperty is that the
kernel autodiscovers all possible devices, and then
autoactivates them, including partition scanning, and then upcalls
the appallingly misdesigned udev
subsystem to ensure devices
are mounted or started as soon as possible.
The proper UNIX-style logic would be for the default to be
inverted, that is for the kernel to initiate discovery of
devices only on user request, and then to activate discovered
devices again only on user request, and to mount or start them
again only on user request. With the ability for the system
startup scripts to assume those user requests on boot, but
with the ability for the user to override the default. But
then the Linux kernel designers
have even
forgotten to specify an abstract device state machine, so it
does not seem surprising that an improper activation logic is
used.
So I have previously remarked that
many web pages keep the CPU busy
and that
laptops and handhelds are limited by heat
and now I am too a double victim: in the past couple of weeks
as I have been looking at news and forum
sites like The Guardian my laptop
(which I have been
using as my main system)
has shut down abruptly a few times because of overheating,
caused entirely by CPU load from free-running Javascript in
web pages.
This a graph (using psensor) of the effect of closing a JavaScript tab containing a Disqus forum threads on CPU usage and temperature:

This is in part due to having a somewhat older CPU chip that does not throttle its clock when it gets hotter, but that in a sense would be cheating: a nominally fast CPU that almost transparently becomes slow when it runs at its rated speed.
There is no workaround: like many I use browser extensions that disable JavaScript code (for example NoScript) but several sites insist on dynamic content generation or update via JavaScript, but once a site is given free access to a browser's JavaScript virtual machine they can take as much advantage as possible. Like many I think that executable content is a very bad idea for several reasons, but it is here to stay for a while. Let's hope that enough handheld users scald their hands or laps or suffer from extreme slowness because of executable content sites that they become less popular.
I have long used auto-mounters
like
am-utils
(once known as AMD)
and recently the Linux-native
autofs5
as a more UNIX-style alternative to complex and insecure
schemes based on MS-Windows like udev-based mounting
on attachment of a network device, as mounting on attempted
access and is both safer and results on shorter
mounting periods. Because of this I have written that
script for autofs5
that turns /etc/fstab into an auto-mount map.
Since recently I upgrade my NFS server configuration I also decided to look at, being somewhat related, my auto-mounting situation, which has had two slightly annoying problems:
The motivation in both cases is that I reckon it is a good practice to leave filetrees umounted as much as possible, and mount them only for the period where they are needed, because:
cleanand no not need checking and recovery.
My investigation about the NFS server Ganesha and auto-unmounting shows that Ganesha opens an exported filetree's top directory on startup, and this means it won't be mounted only if accessed by clients:
# lsof -a -c ganesha.nfsd /fs/*/. COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ganesha.n 27646 root 5r DIR 0,43 918 256 /mnt/export1/. ganesha.n 27646 root 6r DIR 0,47 84 256 /mnt/export2/. ganesha.n 27646 root 7r DIR 8,8 16384 5 /mnt/export3/. ganesha.n 27646 root 8r DIR 8,38 4096 5 /mnt/export5/. ganesha.n 27646 root 9r DIR 0,51 106 256 /mnt/export6/. ganesha.n 27646 root 10r DIR 0,55 156 256 /mnt/export7/.
The problem with both GNOME and
KDE is that their open-file menus
and their file managers are not designed to be UNIX-like,
where there is a single tree of directories with
user-invisible mount points, but they are designed to
resemble MS-Windows
(and MacOS X) in having a main
filetree and a list of volumes
with
independent and separate filetrees. The other systems do this
because on those systems by default when a mountable volume is
attached to the system it is mounted statically until it is
detached, and they don't have a UNIX-like mount-on-access
behaviour.
Because of this they open the system table of mountpoints and read a list of those mountpoints and access them periodically to get their status, and this of course triggers automounting and constant automounmting. This has caused a number of complaints (1, 2, 3, 4), and fortunately these have resulted in some ready-made solutions for GNOME, and similar ones for KDE:
The problem is that GNOME uses a filesystem layer and daemons called GVFS that by default mounts all mount-points listed in system configuration files. This can be disabled in three ways:
gsettings set org.gnome.desktop.media-handling \ automount false gsettings set org.gnome.desktop.media-handling \ automount-open false
[org/gnome/desktop/media-handling] automount=false automount-open=falseand then running dconf update.
KDE used the kio system, but that is not quite involved, instead there is an automounter daemon per-user, and some common plugins mount by default any available mount-points. To disable all these for a user:
Devicesplugin is disabled.
Placespanel mark as hidden all mountpoints.
Only automatically mount removable media that has been manually mounted beforeand disable the other two options, and
Forget Devicethose listed under
Device Overrides(not really sure about this).
Removable devices automounter.
There is a patch to disable mount-point auto-mounting entirely (but only for those of type autofs) but is is not in the KDE version I am using.
Update 180314 Added to the KDE steps to disable the Device Notifier in the System Tray Settings.
So I am using Btrfs, despite it having some design and implementation flaws in its more advanced functionality, because it is fairly reliable as a single device filesystem with checksums and snapshots.
Because of its somewhat unusual redirect-on-write (a variant
of COW) design and
its many features it has somewhat surprising corner cases, and
one of them is that
direct IO
writes
does not update the block checksums (and direct IO reading does
not verify them).
Note: this does not mean that checksums
are missing when block is written by direct IO: as the above
mailing list post says, they are computed when the write is
initiated, but the block can still be modified by the
application after that, and the already-computed checksum is
not updated, because the application has no way to indicate,
but initiating a second write, that the block has been updated.
That is direct IO does not support
stable writes
which is problem in any filesystem, but with Btrfs can result
in the block and checksum not matching.
If the block is modified before the write actually starts,
the block written to persistent storage will be actually
correct and consistent, but the checksum will be wrong; if the
block is modified while the write is in progress, it
is possible for the write to contain part original block and
part updated block, and the block will be consistent and the
checksum wrong. Note that in the case of block in chunks with
profiles that have redundancy more complicated cases can
arise: for example for a block with a raid1 profile
the block checksum can be computed, and the block can be
written from memory before it is modified to one copy, and
after it is modified to the other.
On reads the checksums are indeed checked, but no error is
returned to the application if they fail to verify, only a
warning is printed to the system log. This is because it is
possible for the block to be correct and the checksum wrong.
Update 170813: An earlier report that non-stable writes can be an issue with nfs-kernel-server was unfortunately optimistic because of an unclear error report. When nfs-kernel-server reads from Btrfs volumes the block checksums are read and checked but not verified, and in case of check failure a warning is printed by no error is returned. That means that potentially NFS clients get corrupted block without any error indication, despite the presence of checksums, as reported in this IRC conversation:
2017-02-20 14:32:28 <multicore> darkling: with direct-io csums errors don't result in I/O errors
2017-02-20 14:33:01 <multicore> so do just a nfs share from a btrfs and feed gargage to your clients :/
...
2017-02-20 14:51:55 <Walex> Do direct IO *writes* update checksums?
2017-02-20 14:52:12 <Ke> yes
...
2017-02-20 14:52:28 <Walex> Ke: Ahh so only read don't check them.
2017-02-20 14:53:19 <Ke> Walex: not sure, but the problem is that pages that are modeified during the write will not get updated checksums accordingly
2017-02-20 14:53:53 <multicore> Walex: during DIO reads there's a csum error logged but it doesn't result in EIO
2017-02-20 14:54:25 <Walex> Ke: so direct IO writes don't actually update checksums. My question was not about EIO, it was to update the "Gotchas" section
2017-02-20 14:54:57 <Walex> Is it fair to say that Direct IO reads and writes simply *ignore* checksums?
2017-02-20 14:55:03 <Ke> they do update them to match whatever they read when they read it
2017-02-20 14:55:32 <Ke> when writing that is
2017-02-20 14:55:47 <Ke> the page is not write protected during DIO
2017-02-20 14:55:57 <Ke> it can be modified at any time
...
2017-02-20 14:56:23 <Walex> Ke: does direct IO read verify checksums?
2017-02-20 14:56:28 <Ke> no idea
...
2017-02-20 14:56:46 <multicore> Walex: yes
2017-02-20 14:57:40 <Walex> multicore: so direct IO read and write do the checksum thing, but a block written with direct IO may be modified after the checksum has been computed.
2017-02-20 14:57:52 <Walex> modified in memory I mean.
2017-02-20 14:58:25 <Walex> so the issue is "stable" writes I guess.
2017-02-20 14:58:46 <multicore> Walex: i don't know
2017-02-20 14:58:47 <Walex> I am asking actually, not stating this.
2017-02-20 14:59:53 <Walex> multicore: because if the NFS kernel server does direct IO to Btrfs files, then what happens to checksums during direct IO is a rather big issue.
2017-02-20 15:05:20 <multicore> Walex: i was saved by logcheck because it mailed me about the csum error, had to delete the file from nfs server + client and recover from backups
...
2017-02-20 15:08:23 <multicore> Walex: i was told by someone that with raid1 + csum error the error is fixed but i haven't verified it...
2017-02-20 15:08:34 <multicore> Walex: ...with DIO...
...
2017-02-20 15:11:03 <multicore> this is the reason why i was asking: "<multicore> is there a patch around that turns DIO csum errors to EIO instead just logging the error?"
Note: it is not clear why the
nfs-kernel-server checks but does not verify
checksums. Perhaps when it writes there is a stable writes
issue similar to that arising
from direct IO. Also, in both the direct IO and
nfs-kernel-server read cases, if a checksum fails on
read, and there is enough redundancy to reconstruct valid
block, it will be reconstructed. But may fail in the worst
cases, where the block is valid but the checksum is wrong, or
where there are two copies of the block, but the write was not
stable on only one of them.
The obvious solution for NFS access to Btrfs volumes is to use the NFS daemon server Ganesha which runs like the SMB/CIFS daemon server Samba as a user process using ordinary IO, like many server daemons for other local and distributed filesystems. A kernel based server is going to have lower overheads, but for a file server the biggest costs are in storage and in network transfers, and running in user mode is comparatively a very modest cost.
Ganesha is something that I kept looking at, and years ago it was not quite finished and awkward to install and poorly documented. It is currently instead fairly polished, it is a standard package for Ubuntu, and newer versions are easily obtained via a fairly well maintained Ubuntu PPA.
It is still not very well documented, and in particular the existing example configurations are overly simplistic, as well as with some default paths not quite right for my Ubuntu 14 system, so here is my own example:
# /usr/share/doc/nfs-ganesha-doc/config_samples/config.txt.gz
# /usr/share/doc/nfs-ganesha-doc/config_samples/export.txt.gz
# https://github.com/nfs-ganesha/nfs-ganesha/wiki/Ganesha-config
NFS_CORE_PARAM
{
# https://github.com/nfs-ganesha/nfs-ganesha/wiki/CoreParams
Nb_Worker =32;
# Compare the port numbers with those in
# /etc/default/nfs-kernel-server (MNT_Port)
# /etc/default/quota (Rquota_port)
# /etc/modprobe.d/local.conf (NLM_Port)
# options lockd nlm_udpport=893 nlm_tcpport=893
# /etc/sysctl.conf (NLM_Port)
# fs.nfs.nlm_tcpport=893
# fs.nfs.nlm_udpport=893
NFS_Protocols =4;
NFS_Port =2049;
NFS_Program =100003;
MNT_Port =892;
MNT_Program =100005;
Enable_NLM =true;
NLM_Port =893;
NLM_Program =100021;
Enable_RQUOTA =true;
Rquota_Port =894;
Rquota_Program =100011;
Enable_TCP_keepalive =false;
Bind_addr =0.0.0.0;
}
NFSV4
{
DomainName ="WHATEVER";
IdmapConf ="/etc/idmapd.conf";
}
NFS_KRB5
{
Active_krb5 =true;
# This could be "host" to recycle the host principal for NFS.
PrincipalName ="nfs";
KeytabPath ="/etc/krb5.keytab";
CCacheDir ="/run/ganesha.nfs.kr5bcc";
}
EXPORT_DEFAULTS
{
Protocols =4;
Transports =TCP;
Access_Type =NONE;
SecType =krb5p;
Squash =Root_Squash;
}
EXPORT
{
Access_Type =RW;
SecType =krb5p;
Squash =Root_Squash;
Export_ID =1;
FSAL { Name="XFS"; }
# Must not have symlinks
Path ="/var/data/pub";
Pseudo ="/var/data/pub";
PrefRead =262144;
PrefWrite =262144;
PrefReadDir =262144;
}
Two of the interesting aspects of Ganesha is that it can
serve not just NFSv3 and NFSv4, but also NFSv4.1, pNFS and
even the
9p protocol
and has specialized backends called
FSAL
for
various type of underlying filesystems,
notably
CephFS
and
GlusterFS
but also various other cluster filesystems, plus XFS and
ZFS. The backends for the cluster filesystems give direct
access to those filesystems without the need of a local
client for them, which reduces considerably complications
and overheads.
My experience with Ganesha has been so far very positive, the speed is good as expected, and it is rather easier to setup and configure than nfs-kernel-server in particular as to Kerberos authentication; also as to configuration, administration, monitoring and investigation, being a user-level daemon.
Remote two-factor authentication requires knowledge or possession of two authenticators, usually one is known and the other is possessed. The obvious example is a password and a mobile phone number that received a once-only validation code, or a password and a random one-time-password from a pre-generated list.
However in many cases there is a weaker form of two-factor authentication, where the authenticator unlocks some container holding the effective authenticator, because in that case access requires both knowledge of the authenticator and possession of the container. This case is common where the authenticator is the passphrase of some encrypted file containing the real authenticator, for example an SSH key passphrase and a the SSH private key file it encrypts.
But there is a more common case that should not be forgotten: possession of the computer itself, that is access can only be local and physical. This does not mean that the computer is only accessible locally, but that the authenticator only works locally.
Now these cases seem fairly obvious, but there is an important case where the distinction matters: when providing an authenticator based on knowledge and it can be observed by third parties, such as when a key-logger is present on the system, or a camera or microphone records the typing of the authenticator. In these cases the authenticator can be recorded. For organizations with resources putting a tiny key-logger in the target system or a tiny camera or a tiny microphone in the room containing can be pretty easy for regular offices and residences, but there is a far more common case: use of a system, such as a laptop, in public, such as on a train, bus, or in a coffee house or internet cafè, because surveillance cameras are extremely common.
Only explicit or implicit two-factor authentication helps against that. If that is a concern all remote accesses must involve two-factor authentication, and all one-factor accesses must be strictly local.
So for example on a UNIX/Linux systems passwd authentication should only be allowed for local log-in (getty etc.) and only key based authentication should be allowed for remote log-in (SSH etc.). Also, the local login password can be further augmented, in case loss of possession of the system is a concern, with an OTP system.
Note: Indeed for quite critical systems a site I know uses password plus OTP for local logins, and manually verified SSH keys for remote access.
In particular where is a concern with observation of passwords, Kerberos (and this includes MS-AD) passwords should not be allowed for remote log-in, because the password can be used then to get remote access entirely by itself; also kinit by the same argument should not be used with just a password.
Fortunately some provision has been made for two-factor authentication using Kerberos and smartcards/certificates (PKINIT) and tentative approaches with OTP (FAST, PAKE).
There is an alternative: to extract from Kerberos a suitable
keytab
and put it into an encrypted
file. Then knowing the passphrase for the encrypted keytab is
needed to use it with kinit, and possession of that
passphrase and the keytab are both necessary. This option has
some downsides, and should be carefully considered.
In theory all passwords and passphrases should be unique, but for primary login (whether local or remote) passwords that is quite tedious. The local login password and the passphrases used to encrypt local copies of the SSH keys (and of the Kerberos keytab) can be the same, as they all require possession of the system or encrypted file; the OTP and Kerberos passwords however need to be different, or else those who figure out the login passwords can use them to achieve local access when possession of the system has been obtained, or remote access via Kerberos.
Note: if local or remote login is achieved by an adversary, all encryption passphrases can be trivially obtained on first use, by installing a key-logger daemon.
I have recently learned that in Btrfs the number of links per directory (as returned by the stat(2) system call) is always 1, and this number has the special meaning that it is not known how many subdirectories a directory has, as a directory always has at least 2 sudirectories. Also the number of inodes maximum and free in a Btrfs filetree is always reported as 0 (as returned by the statfs(2) system call), which has the special meaning that the actual number is not known, while a filetree has always at least 1 inode for the local root directory.
These are significant changes in the semantics of UNIX-style filesystems, and other filesystem types have adopted them. It makes certainly easier to adopt filesystem implementations in which hard-links and directories are implement differently from the tradition in which a directory is a simple list of hard links which consist of link name and inode number.
The relevant code within the popular findutils collection and some other has been updated, but there is a lack of documentation of the special meaning of a link count of 1 for directories or 0 for maximum inodes and free inodes.
They are fairly significant changes, because they are obviously not backwards compatible: other filesystems with fluid statistics use the largest number, which is backwards compatible, becaue both number of links to a directory and number of free or user inodes are used as upper limits in loops that also rely on conditions.
Three years ago IPv6 traffic was seen by Google as hitting 2% of total IP traffic and it is quite remarkable that today it hit 14.22%, and that is 14% of a rather bigger total. It is also remarkable that:
At 14% of total traffic IPv6 is now commercially relevant, in the sense that services need to be provided over IPv6, as IPv6 users cannot be ignored, and accordingly even mass market ISPs like Sky Broadband UK have been giving IPv6 connectivity as standard for several months and it is therefore sad but understandable that transition services like SixXS are being closed down:
Summary
SixXS will be sunset in H1 2017. All services will be turned down on 2017-06-06, after which the SixXS project will be retired. Users will no longer be able to use their IPv6 tunnels or subnets after this date, and are required to obtain IPv6 connectivity elsewhere, primarily with their Internet service provider.
My current ISP does not yet support IPv6, but it has a low delay to a fairly good 6to4 gateway, so I continue to use 6to4 with NAT.
In the previous note about a simple speed test of several Linux filesystems star was used because unlike GNU tar it does fsync(2) before close(2) of a written file, and I added that for Btrfs I also ensured that metadata was (as per default) duplicated as per the dup profile, and these were challenging details.
To demonstrate how challenging I have done some further
coarse tests on a similar system, copying from a mostly
root
filesystem (which has many small
files) to a Btrfs filesystem, with and without the
star option -no-fsync and with Btrfs
metadata single and dup in order of
increasing write rate with fsync:
| Btrfs target |
write time | write rate | write sys CPU |
|---|---|---|---|
| dup fsync | 381m 28s | 3.3MB/s | 13m 14s |
| single fsync | 293m 26s | 4.2MB/s | 13m 15s |
| dup no-fsync | 20m 09s | 61.7MB/s | 3m 50s |
| single no-fsync | 19m 58s | 62.3MB/s | 3m 41s |
For comparison the same source and target and copy command with some other filesystems also in order of increasing write rate with fsync:
| other target |
write time | write rate | write sys CPU |
|---|---|---|---|
| XFS fsync | 318m 49s | 3.9MB/s | 7m 55s |
| XFS no-fsync | 21m 24s | 58.2MB/s | 4m 10s |
| F2FS fsync | 239m 04s | 5.2MB/s | 9m 09s |
| F2FS no-fsync | 21m 32s | 57.8MB/s | 5m 02s |
| NILFS2 fsync | 118m 27s | 10.5MB/s | 7m 52s |
| NILFS2 no-fsync | 23m 17s | 53.5MB/s | 5m 03s |
| JFS fsync | 21m 45s | 57.2MB/s | 5m 11s |
| JFS no-fsync | 19m 42s | 63.2MB/s | 4m 24s |
Notes:
Source filetree was XFS on a very fast flash SSD, so not a
bottleneck.
Source filetree 70-71GiB (74-75GB) and 0.94M
inodes (0.10M of which directories), of which 0.48M under
1KiB, 0.69M under 4KiB and 0.8M under 8KiB (the Btrfs
allocation block size).
Observed occasionally IO with blktrace and
blkparse and with fsync virtually all IO
was synchronous, as fsync on a set of files of 1
block is essentially the same as fsync on every
block.
Because of its (nearly) copy-on-write nature Btrfs handles
transactions with multiple fsyncs
particularly well.
Obviously fsync per-file on most files is very expensive, and dup file metadata is also quite expensive, but nowhere as much as fsync. A very strong demonstration that the performance envelope of storage system is rather anisotropic. It is also ghastly interesting that given the same volume of data IO with fsync costs more than 3 times the system CPU time as without. Some filesystem specific notes:
soft# dl /mnt/tmp/. Filesystem Type 1G-blocks Used Available Use% Mounted on /dev/sdd3 nilfs2 232G 136G 85G 62% /mnt/tmp soft# du -sm /mnt/tmp/. 72670 /mnt/tmp/.Looking at its operation with vmstat during the fsync copy:
0 0 0 272008 2232692 3826540 0 0 3128 23980 4422 3293 0 2 96 1 0 1 0 0 270892 2233596 3827288 0 0 0 12448 1323 2041 0 1 99 0 0 1 0 0 269900 2234488 3828084 0 0 0 12416 1398 2079 0 1 99 0 0 0 0 0 267296 2235392 3829128 0 0 3492 13068 2385 3288 0 2 96 2 0 0 0 0 265636 2236268 3829932 0 0 0 12072 1243 2003 0 1 98 0 0 0 0 0 262968 2237172 3830992 0 0 0 12384 1297 2107 0 1 99 0 0 0 0 0 261232 2238072 3831932 0 0 0 12192 1335 2078 0 1 99 0 0 0 0 0 253848 2238976 3836124 0 0 3888 12396 3024 4276 0 2 96 2 0 0 0 0 251816 2239872 3837088 0 0 0 12232 1334 2110 0 1 98 0 0 0 0 0 248512 2240772 3838312 0 0 0 19060 3214 2853 1 2 97 0 0 0 0 0 241596 2241680 3842384 0 0 3520 12136 3070 4348 0 2 96 2 0 0 0 0 239300 2242580 3843444 0 0 0 12192 1326 2087 0 2 98 0 0 0 0 0 238152 2243480 3844088 0 0 0 11944 1278 2030 0 1 99 0 0 0 0 0 236104 2244384 3845212 0 0 0 12292 1419 2192 0 2 98 0 0 0 0 0 229360 2245284 3849200 0 0 3476 11900 2828 3970 0 2 96 2 0That is NILFS2 writes to the target filetree a lot more than what is being read from the source filetree. Most likely the reason is that on fsync NILFS2 writes to disk a full log segment even if it has not been filled up. Starting the NILFS2 compactor nilfs_cleanerd on the target filetree brings down the allocated space to be in line with the used space, and perhaps the time taken by the compactor (roughly an extra 30m) to do that should be added to the time to complete the copy.
Having previously mentioned my favourite filesystems I have decided to do again in a different for a rather informative, despite being simplistic and coarse, test of their speed similar to one I did a while ago, with some useful results. The test is:
time star -copy -p -xdot -C /mnt/media . /mnt/tmpThe command chosen is star because unlike most other tar variants it actually fsyncs the file, which to me is quite important to figure out a filesystem's proper profile. It also conveniently has much like pax or cpio a copy-mode.
sysctl vm/drop_caches=1; time star -f - -b 512 -c -p -xdot -C /mnt/tmp . | dd bs=512b of=/dev/zero
# grep -H . /proc/sys/vm/dirty*{bytes,centisecs}*
/proc/sys/vm/dirty_background_bytes:200000000
/proc/sys/vm/dirty_bytes:900000000
/proc/sys/vm/dirty_expire_centisecs:1000
/proc/sys/vm/dirty_writeback_centisecs:100
It would have been better with a value of
dirty_background_bytes and
dirty_expire_centisecs half of those, but I wanted
to give a slightly better chance to (misguided) techniques
like delayed allocation.
It is coarse, it is simplistic, but it gives some useful upper bounds on how filesystem does in a fairly optimal case. In particular the write test, involving as it does a fair bit of synchronous writing and seeking for metadata, is fairly harsh; even if, as the test involves writing to a fresh, empty filetree, pretty much an ideal condition, it does not account at all for fragmentation on rewrites and updates. The results, commented below, sorted by fastest, in two tables for writing and reading:
| type | write time | write rate | write sys CPU |
|---|---|---|---|
| JFS | 148m 01s | 72.4MB/s | 24m 36s |
| F2FS | 170m 28s | 62.9MB/s | 26m 34s |
| OCFS2 | 183m 52s | 58.3MB/s | 36m 00s |
| XFS | 198m 06s | 54.1MB/s | 23m 28s |
| NILFS2 | 224m 36s | 47.7MB/s | 32m 04s |
| ZFSonLinux | 225m 09s | 47.6MB/s | 18m 37s |
| UDF | 228m 47s | 46.9MB/s | 24m 32s |
| ReiserFS | 236m 34s | 45.3MB/s | 37m 14s |
| Btrfs | 252m 42s | 42.4MB/s | 21m 42s |
| type | read time | read rate | read sys CPU |
|---|---|---|---|
| F2FS | 106m 25s | 100.7MB/s | 66m 57s |
| Btrfs | 108m 59s | 98.4MB/s | 71m 25s |
| OCFS2 | 113m 42s | 94.3MB/s | 66m 39s |
| UDF | 116m 35s | 92.0MB/s | 66m 54s |
| XFS | 117m 10s | 91.5MB/s | 66m 03s |
| JFS | 120m 18s | 89.1MB/s | 66m 38s |
| ZFSonLinux | 125m 01s | 85.8MB/s | 23m 11s |
| ReiserFS | 125m 08s | 85.7MB/s | 69m 52s |
| NILFS2 | 128m 05s | 83.7MB/s | 69m 41s |
Notes:
The system was otherwise quiescent.
I have watched the various tests with iostat,
vmstat, and looking at graphs produced by
collectd, displayed by kcollectd and
sometimes I have used blkstat blktrace; I
have also used occasionally used strace to look at
the IO operations requested by star.
Having looked at actual behaviour, I am fairly sure that
all involved filesystem respected fsync semantics.
The source disk seemed at all times to not be the limiting
factor for the copy, in particular as streaming reads are
rather faster, as shown above, than writes.
The first comment on the numbers above is the obscene amount of system CPU time taken, especially for reading. That the system CPU time taken for reading being 2.5 times or more higher than that for writing is also absurd. The test system has an 8 thread AMD 8270e CPU with a highly optimized microarchitecture, 8MiB of level 3 cache, and a 3.3GHz clock rate.
The the system CPU time for most filesystem types is roughly the same, again especially for reading, which indicates that there is common cause that is not filesystem specific. For F2FS the system CPU time for reading is more than 50% of the elapsed time, an extreme case. It is interesting to see that ZFSonLinux, which has uses its own cache implementation, ARC has a system CPU time of roughly 1/3 that of the others.
That Linux block IO involves an obscene amount of system CPU
time to do IO I had noticed already
over 10 years ago
and that the issue has persisted so far is a continuing
assessment of the Linux kernel developers in
charge
of developing the block IO subsystem.
Another comment that applies across all filesystems is that the range of speeds is not that different, all of them had fairly adequate, reasonable speeds given the device. While there is a range of better to worse, this is to be expected from a coarse test like this, and a different ranking will apply to different workloads. What this coarse test says is that none of these filesystems is is particularly bad on this, all of them are fairly good.
Another filesystem independent aspect is that the absolute values are much higher, at 6-7 times better, than those I reported only four years ago. My guess is is this mostly because the previous test involved the Linux source tree which contains a a large number of very small files; but also because the hardware was an old system that I was no longer using in 2012, indeed I had not used since 2006.
As to the selection of filesystem types tested, the presence of F2FS, OCFS2, UDF, NILFS2 may seem surprising, as they are considered special-case or odd filesystems. Even if F2FS was targeted at flash storage, OCFS2 at shared-device clusters, UDF at DVDs and BDs, and NILFS2 at "continuous snapshotting", they are actually all general purpose, POSIX-compatible filesystems that work well on disk drives and with general purpose workloads. I have also added ZFSonLinux, even if I don't like for various reasons, as a paragon. I have omitted a test of ext4 because I reckon that it is a largely pointless filesystem design, that exists only because of in-place upgradeability from ext3, which in turn was popular only because of in-place upgradeability from ext2, when the installed base of Linux was much smaller. Also OCFS2 has a design quite similar to that of the ext3 filesystem, and has some more interesting features.
Overall the winners
, but not large margins,
from this test seem to be F2FS, JFS, XFS, OCFS2. Some filesystem
specific notes, in alphabetical order:
allocation groups, which makes reading slower in this test than for a filesystem that packs tightly all data added to an empty filetree. The advantage of the JFS design is further additions to the filetree have a better chance of being nearer to existing data, improving long term locality.
Some time ago I mentioned an archival disk drive model from HGST which had a specific lifetime rating for total reads and writes, of 180TB per year as compared to the 550TB per year of a similar non-archival disk drive.
The recent series of
IronWolf,
IronWolf Pro and
Enterprise Capacity
disk drives from Seagate which are
targeted largely at
cold storage
use have
similar ratings:
MTBFof 1 million hours).
MTBFof 1.2 million hours).
MTBFof 2 million hours).
It is interesting also that the lower capacity drives
are rated for Nonrecoverable Read Errors per Bits Read,
Max
of 1 per 10E14 and the large ones for 1 in 1E15
(pretty much industry standard), because 180TB per year is
roughly 10E13, and the drives probably are designed to last
5-10 years (they have 3-5 years warranties).
Having just illustrated a simple
confinement mechanism for UNIX/Linux systems
that uses the regular UNIX/Linux style permissions, I should
add that the same mechanism can also replace in one simple
unified mechanism the
setuid
protection domain switching of UNIX/Linux systems. The
mechanism would be to add to each process, along with its effective
id (user/group) what I would now
call a preventive id with the following rules:
confinedto the set of resources accessible by both. Therefore a user that does not fully trust an executable can give access to just the resources it strictly needs to access, by setting permissions so that the id of the file containing the executable can access only those.
Note: there are some other details to take care of, like apposite rules for access to a process via a debugger. The logic of the mechanism is that it is safe to let a process operate under the preventive id of its executable, because the program logic of the executable is under the control of the owner of the executable, and that should not be subverted.
The mechanism above is not quite backwards compatible with the UNIX/Linux semantics because it makes changes in the effective or preventive ids depend on explicit process actions, but it can be revised to be backwards compatible with the following alternative rules:
stickybit set the preventive id of the process is set to the id of that executable file. The sticky bit in effect becomes the confinement bit.
Note: the implementation of either variant of the mechanism is trivial, and in particular adding preventive id fields to a process does not require backward incompatible changes as process attributes are not persistent.
The overall logic is that in the UNIX/Linux semantics for a process to work across two protection domains it must play between the user and group ids; but it is simpler and more general to have the two protection domains identified directly by two separate ids for the running process.
BusinessWeek has an interesting article on some businesses that offer tools to minimize cloud costs and a particularly interesting example they make contains these figures:
Proofpoint rents about 2,000 servers from Amazon Web Services (AWS), Amazon.com’s cloud arm, and paid more than $10 million in 2016, double its 2015 outlay. “Amazon Web Services was the largest ungoverned item on the company’s budget,” Sutton says, meaning no one had to approve the cloud expenses.
$10m for 2,000 virtual machines means $5,000 per year per VM,
or $25,000 over the 5-year period where a physical server
would be depreciated. That buys a very nice physical server
and 5 years of colocation including power and cooling and remote hands
, plus a good margin of saving,
with none of the inefficiencies or limitations of VMs;
actually if one buys 2,000 physical servers and colocation one
can expect substial discounts over $25,000 for a single server
over 5 years.
Note Those 2,000 servers are unlikely to have a large configuration, more likely to be small thin servers for purposes like running web front-ends.
The question is whether those who rent 2,000 VMs from AWS are
mad. My impression is that they are more foolish than mad, and
the key words in the story above are no one had to approve
the cloud expenses
. The point is not just lack of approval
but that cloud VMs became the default option, the path of
least resistance for every project inside the company.
The company probably started with something like 20 VMs to
prototype their service to avoid investing in a fixed capital
expense, and then since renting more VMs was easy and
everybody did it, that grew by default to 2,000 with nobody
really asking themselves for a long time whether a quick and
easy option for starting with 20 systems is as sensible when
having 2,000.
Cutting VM costs by 10-20% by improving capacity utilization is a start but fairly small compard to rolling their own.
I have written before that cloud storage is also very expensive, and cloud systems also seem to be. Cloud services seem to me premium products for those who love convenience more than price and/or have highly variable workloads, or those who need a builting content distribution network. Probably small startups are like that, but eventually they start growing slowly or at least predictably, and keep using cloud services by habit.
There are two problems in access control,
read-up
and write-down
,
and two techniques (access lists and capabilities). The
regular UNIX access control is aims to solve the read-up
problem using an abbreviated form of access control lists,
and POSIX added extended access control lists.
Preventing read-up with access control lists is a solution
for preventing unintended access to resources by
users, but does not prevent unintended access to
resources by programs, or more precisely by the
processes running those programs, because a process running
with the user's id can access any resource belonging to that
user, and potentially transfer the content of the resource to
third parties such as the program's author, or someone who has
managed to hack
into the process running
that program. That is, it does not prevent write-down.
The typical solution to confinement is use some form of container, that is to envelope a process running a program in some kind of isolation layer, that prevents it from accessing the resources belonging to the invoking user. The isolation layer can be usually:
containers, (some aspects of them I mentioned in a recent article here) or QEMU
virtual machines, which work by hiding resource a program's process should not access.
mandatoryaccess control list systems like AppArmor or SELinux, which work by listing explicitly which resources a process running a program can access, all others being disallowed.
There is a much simpler alternative (with a logic similar to distinct effective and real ids for inodes) that uses the regular UNIX/POSIX permissions and ACLs: to create a UNIX/POSIX user (and group) id per program, and then to allow access only if both the process owner's id and the program's id have access to a resource.
This is in effect what SELinux does in a convoluted way, and is fairly similar also to AppArmor profile files, which however suffer from the limitation of imposing policies to be shared by all users.
Instead allowing processes to be characterized by both the user id of the process owner, and the user id of the program (and similarly for group ids), would allow users to make use of regular permissions and ACL to tailor access by programs to their own resources, if they so wished.
Note: currently access is granted if the effective user id or the effective group id of a process owner have permission to access a resource. This would change to granting access if [the process effective user id and the program user id both have permission] or [the process effective group id and the program group id both have permission]. Plus some additional rules, for example that a program id of 0 has access to everything, and can only be set by the user with user id 0.
Note: of course multiple programs could share the same program user and group id, which perhaps should be really called foreign id or origin id.
At some point in order to boost the cost and lifestyles of their executive most IT technology companies try to move to higher margin market segments, which usually are those with the higher priced products. In the case of mainframes this meant an abandonment of lower priced market segments to minicomputer suppliers. This created a serious skills problem: to become a mainframe system administrator or programmer a mainframe was needed for learning, but mainframe hardware and operating systems were available only in large configurations at very high price levels, and therefore used only for production.
IBM was particularly affected by this as they really did not want to introduce minicomputers with a mainframe compatible hardware and operating system, to make sure customers locked-in to them would not be tempted to fall back on a minicomputers, and the IBM lines of minicomputers were kept rigorously incompatible with and much more primitive than the IBM mainframe line. Their solution, which did not quite succeed, was to introduce PC-sized workstations with a compatible instruction set, to run on them a version of the mainframe operating system, and even to create plug-in cards for the IBM PC line, all to make sure that the learning systems could not be used as cheap production systems.
Note: The IBM 5100 PC-sized mainframe
emulator became an interesting detail in the story of time traveller
John Titor.
The problem is more general: in order to learn to configure and program a system, one has to buy that system or a compatible one. Such a problem is currently less visible because most small or large systems are based on the same hardware architectures, the intel IA32 or AMD64 ones, and one of two operating system, MS-Windows or Linux, and a laptop or a desktop thus have the same runtime environment as a larger system.
Currently the problem happens in particular for large clusters for scientific computing, and it manifests particularly for highly parallel MPI programs. In particular many users of large clusters develop their programs on their laptops and desktops, and these programs read data from local files using POSIX primitives, rather than using MPI2 IO primitives. Thus the demand for highly parallel POSIX-like filesystems like Lustre that however are not quite suitable for highly parallel situations.
The dominant issue of such programs is that the issues that arise with them, mostly synchronization and latency impacting speed, cannot be reproduced on a workstation, even if it can run the program with MPI or other frameworks. Many of these programs cannot even be tested on a small cluster, because their issues arise only at grand scale, and may be even different on different clusters, as they may be specific to the performance envelope of the target.
The same problems happen with OpenMP, which is designed for shared memory systems with many CPUs: while even laptops today have some CPUs that share memory, the real issues happens with systems have have a few dozen CPUs and non-uniform shared memory, and with systems that have several dozen or even hundreds of CPUs, and the issue they have also arise only at scale, and vary depending on the details of the implementation.
It is not a simple problem to solve, and is a problem that limits severely the usefulness of highly parallel programs on large clusters, as it limits considerably their ecosystem.
The bottom of this site's index page has a list of sites and blogs similar to this in containing opinions about computer technology, mostly related to Linux and system and network engineering and programming, and I have been recently discovered a blog by the engineers and programmers offering their services via one of the main project based contract work sites.
The blog like every blog has a bit of a promotional role for the site and the contract workers it lists, but the technical content is not itself promotional, but has fairly reasonable and interesting contributions.
I have been particularly interested by a posting on using
Linux based namespaces
to achieve program and process confinement
.
It is an interesting topic in part because it is less than wonderfully documented, and it can have surprising consequences.
The posting is a bit optimistic in arguing that
using namespacing, it is possible to safely execute
arbitrary or unknown programs on your server
as there are documented cases of (moderately easy) programs breeaking out
of containers and even virtual
machines. But namespace do make it more difficult to do bad
things and often raising the level of cost
and difficulty achieves good-enough security.
Note: The difficulty with namespaces and isolation is that namespaces are quite complicated mechanisms that need changes to a lot of Linux code, and they are a somewhat forced retrofit into the logic of a POSIX-style system, while dependable security mechanism need to be very simple to describe and code. Virtual machine systems are however even more complicated and error prone.
The posting discusses process is, network interface, and mount namespaces, giving simple illustrative examples of code to use them, and briefly discusses also user id, IPC and host-name namespaces. Perhaps user id namespaces would deserve a longer discussion.
The posting indeed can serve as a useful starting point
for someone who is interested in knowing more a complicated
topic
. It would be nice to see it complemented by
another article on the history and rationale of the design of
namespaces and related ideas, and maybe I'll write something
related to that in this blog.
With great surprise I have received recently for the first
time in a very, very long time a legitimate and thus
non-spam
unsolicited commercial email.
The reason why unsolicited commercial emails are usually considered spam is that they are as a rule mindless time wasting advertising, usually automated and impersonal, and come in large volume as a result. For the email I received it was unsolicited and commercial, but it was actually a reasonable business contact email specifically directed at me from an actual person who answered my reply.
Of course there are socially challenged people who regard any unsolicited attempt at contact as a violation, (especially from the tax office I guess :-)), but unsolicited contact is actually pretty reasonable if done in small doses and for non-trivial personal or business reasons.
It is remarkable how rare they are and that's why I use my extremely effective anti-spam wildcard domain scheme.
While chatting the question was raised of what is the Internet
. From a technical point of view that
is actually an interesting question with a fairly definite
answer:
Internets, one is an IPv4
internetand the other is an IPv6 internet, and they are entirely distinct and incompatible, even if usually they use the same physical cabling infrastructure, and have very similar designs, and nearly all IPv6 Internet nodes are also on the IPv4 Internet.
There are IPv4 or IPv6 internets that are distinct from the two Internets, but usually they adopt the IANA conventions and have some kind of gateway (usually it needs to do NAT) to the two Internets.
Note: these internets use the same IPv4 or IPv6 address ranges as the two Internets, but use them for different hosts. Conceivably they could also use the same port numbers for different services: as port 80 has been assigned by IANA for HTTP service, a separate internet could use port 399. But while this is possible I have never heard of an internet that uses assigned numbers different from the IANA ones, except for the root DNS servers.
But it is more common to have IPv4 or IPv6 internets that differ from the two Internets only in having a different set of DNS root name server addresses, but are otherwise part, at the transport and lower levels, of the two Internets.
There is a specific technical term to indicate the consequences of having different sets of DNS root name servers, naming zone. Usually the naming zones for internets directly connected to the two Internets overlap and extend with those of the two Internets, they just add (and sometimes redefine or hide) the domains of the Internets.
Note: Both the IPv4 and the IPv6 Internets share the same naming zone, in the sense that the IPv4 DNS root servers and the IPv6 DNS root server serve the same root zone content by convention. This is not necessarily the case at deeper DNS hierarchy levels: it is a local convention whether a domain resolves to an IPv4 and IPv6 address that are equivalent as in being on the same interface and the same service daemons being bound to them.
Two relatively new filesystem designs and implementations for Linux are F2FS and Bcachefs.
The latter is a personal project of the author of Bcache, a design to cache data from slow storage onto faster storage. It seems very promising, and it is one of the few with full checksumming, but it is not part yet of the default Linux sources, and work on it seems to be interrupted, even if the implementation of the main features seems finished and stable.
F2FS was initially targeted at flash storage devices, but is generally usable as a regular POSIX filesystem, and performs well as such. Its implementation is also among the smallest with around half or less the code size of XFS, Btrfs, OCFS2 or ext4:
text data bss dec hex filename 237952 32874 168 270994 42292 f2fs/f2fs.ko
Many congratulations to its main author Jaegeuk Kim, a random Korean engineer in the middle of huge corporation Samsung, for his work.
Since the work has been an official Samsung project, and F2FS is part of the default Linux sources, and is widely used on Android based cellphone and tablet devices, it is likely to be well tested and to have long term support.

{kind=link}
{kind=link}
{kind=link}